





È necessario compilare Tensorflow™?
In solo due anni, Tensorflow™ si è imposta come una delle librerie più diffuse per il deep machine learning. Come per lo sviluppo di qualsiasi prodotto software, è essenziale raggiungere le massime prestazioni possibili con i progetti Tensorflow™.
Un metodo efficace per aumentare la velocità di calcolo consigliato da Google consiste nell'evitare l'uso di un pacchetto precompilato della libreria Tensorflow™, da sostituire con una versione di Tensorflow™ compilata direttamente dal codice sorgente. Di recente è stato condotto uno studio per testare il metodo suggerito da Google, con lo stesso progetto che è stato avviato utilizzando Tensorflow™ senza il supporto della piattaforma CUDA® installata, con tre modalità diverse:
- utilizzando un pacchetto precompilato;
- compilazione diretta dal codice sorgente, senza supportare le istruzioni CPU;
- compilazione diretta dal codice sorgente, supportando le istruzioni CPU (AVX, AVX2, FMA, ecc.)
Sono stati effettuati anche dei test sulla libreria Tensorflow™ con il supporto per la piattaforma CUDA®. I seguenti risultati dei test sono stati utilizzati come benchmark:
- Test con dati reali. Una rete di tipo Inception-ResNet-v2 è stata formata e utilizzata per riconoscere il sesso delle persone con l'aiuto del set di dati di FaceScrub (http://vintage.winklerbros.net/facescrub.html).
- Test sintetici tratti dal sito web ufficiale di TensorFlow™. Il modello della rete neurale è Inception v3 (https://www.tensorflow.org/lite/performance/measurement).
I test sono stati effettuati sul server con la seguente configurazione (www.leadergpu.it):
- GPU: NVIDIA® Tesla® P100 (16 GB)
- CPU: 2 x Intel® Xeon® E5-2630v4 2.2 GHz
- RAM: 128 GB
- SSD: 960 GB
- Ports: 40 Gbps
- OS: CentOS 7
- Python 2.7
- TensorFlow™ 1.3
Comandi per l'installazione di Tensorflow™ senza supporto CUDA®:
Installazione di Tensorflow™ con un pacchetto precompilato:
# pip install tensorflowInstallazione di Tensorflow™ con compilazione diretta dal codice sorgente:
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
# ./configure-
per la compilazione senza il supporto per i comandi della CPU:
# bazel build -c opt //tensorflow/tools/pip_package:build_pip_package -
per la compilazione con il supporto per i comandi della CPU:
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg # pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whl
Test con dati reali e dati sintetici senza il supporto di CUDA
Comandi per avviare una rete per i test con dati reali:
# cd gender_net
# python download_data.py
# python convert_data_FS.py
# time python model_FS_mulGPU_v3.pyComandi per l'esecuzione dei test con dati sintetici:
# mkdir ~/Anaconda
# cd ~/Anaconda
# git clone https://github.com/tensorflow/benchmarks.git
# cd ~/Anaconda/benchmarks/scripts/tf_cnn_benchmarks
# python tf_cnn_benchmarks.py --devicecpu model --inception3 --batch_size 32 --data_format NHWC --num_batches 40
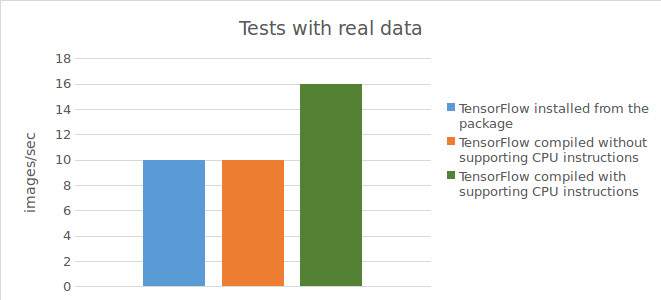
Test di Tensorflow™, installato con un pacchetto precompilato:
Risultati dei test con dati reali:
10 images / sec;
tempo di esecuzione script di test
= 20m55s.
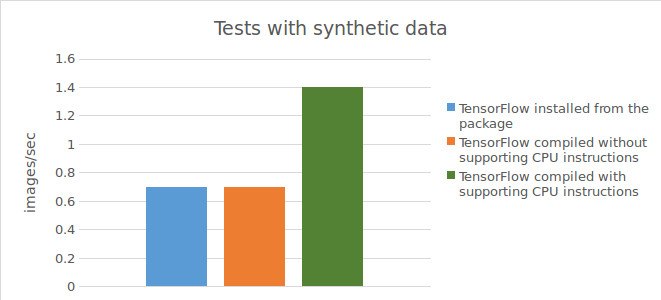
Risultati dei test con dati sintetici:
0,73 images/sec;
tempo di esecuzione script di test
= 36m25s.
Test di Tensorflow™, compilazione diretta dal codice sorgente senza il supporto per le istruzioni CPU:
Risultati dei test con dati reali:
10 images/sec;
tempo di esecuzione script di test
= 20m55s.
Risultati dei test con dati sintetici:
0,74 images/sec;
tempo di esecuzione script di test
= 36m21s.
Test di Tensorflow™, compilazione diretta dal codice sorgente con il supporto per le istruzioni CPU:
Risultati dei test con dati reali:
15-16 images/sec;
tempo di esecuzione script di test
= 14m13s.
Risultati dei test con dati sintetici:
1,44 images/sec;
tempo di esecuzione script di test
= 18m40s.
I risultati dei test sono illustrati nel seguente grafico.
Comandi per l'installazione di Tensorflow™ con il supporto di CUDA®:
Installazione di Tensorflow™ con un pacchetto precompilato:
# pip install tensorflowInstallazione di Tensorflow™ con compilazione diretta dal codice sorgente:
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
#./configure
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 --config=cuda //tensorflow/tools/pip_package:build_pip_package
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
# pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whlI comandi per avviare le reti sono simili ai comandi dei test precedenti, tranne il comando per l'esecuzione dello script per l'avvio della formazione della rete con dati sintetici:
# python tf_cnn_benchmarks.py --num_gpus=1 --model inception3 --batch_size 32Test con dati reali e dati sintetici con il supporto di CUDA:
Test di Tensorflow™, installato con un pacchetto precompilato:
Risultati dei test con dati reali:
214 images/sec.
Risultati dei test con dati sintetici:
126,33 images/sec.
Test di Tensorflow™, compilazione diretta dal codice sorgente con il supporto per le istruzioni CPU:
Risultati dei test con dati reali:
215 images/sec.
Risultati dei test con dati sintetici:
126,34 images/sec.
Per riassumere i risultati dei test condotti, l'utilizzo di Tensorflow™ con compilazione diretta dal codice sorgente (con il supporto per le istruzioni CPU) si traduce in un aumento significativo (1,5 volte con dati reali e 2 volte con dati sintetici) della velocità dei calcoli sulla CPU. Lavorando con una GPU, invece, l'utilizzo di Tensorflow™ con compilazione diretta dal codice sorgente non produce risultati migliori rispetto all'utilizzo di Tensorflow™ installato con un pacchetto precompilato.