





Stable Diffusion: LoRA selfie

È possibile creare il primo set di dati utilizzando una semplice fotocamera e uno sfondo abbastanza uniforme, come una parete bianca o una tenda oscurante monotona. Per un set di dati di esempio, ho utilizzato una fotocamera mirrorless Olympus OM-D EM5 Mark II con obiettivo 14-42 in kit. Questa fotocamera supporta il controllo remoto da qualsiasi smartphone e una modalità di scatto continuo molto veloce.
Ho montato la fotocamera su un treppiede e ho impostato la priorità di messa a fuoco sul viso. Poi ho selezionato la modalità in cui la fotocamera cattura 10 fotogrammi consecutivi ogni 3 secondi e ho avviato il processo. Durante la ripresa, ho girato lentamente la testa nella direzione selezionata e ho cambiato direzione ogni 10 fotogrammi:

Il risultato è stato di circa 100 fotogrammi con uno sfondo monotono:
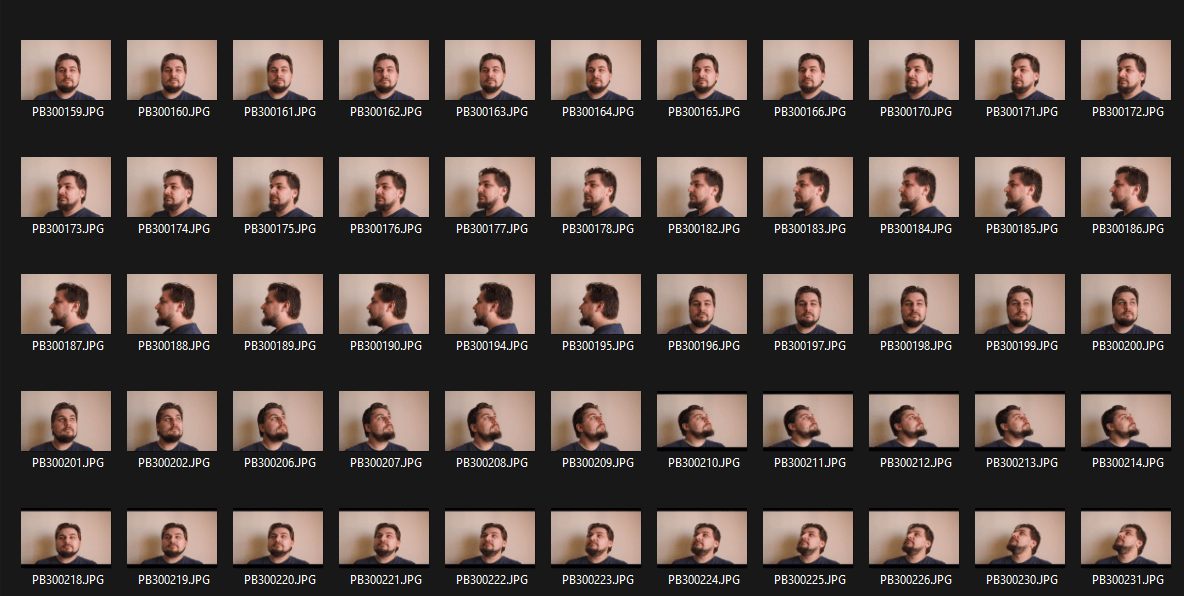
Il passo successivo consiste nel rimuovere lo sfondo e lasciare il ritratto su uno sfondo bianco.
Eliminare lo sfondo
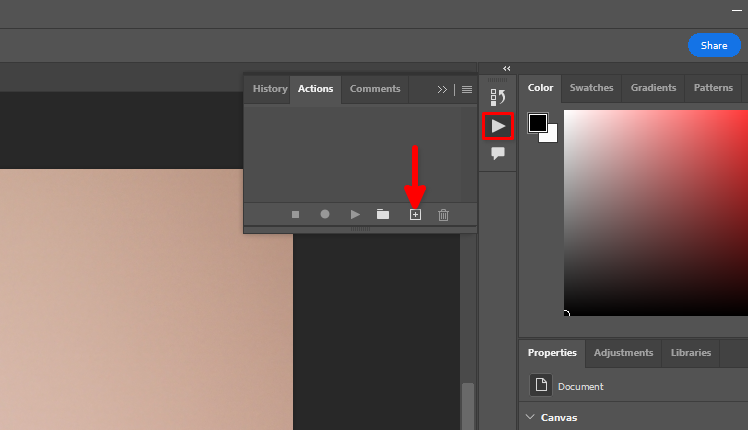
È possibile utilizzare la funzione standard di Adobe Photoshop Remove background e l'elaborazione in batch. Memorizziamo le azioni che vogliamo applicare a tutte le immagini di un set di dati. Aprire un'immagine qualsiasi, fare clic sull'icona del triangolo, quindi fare clic sul simbolo +:
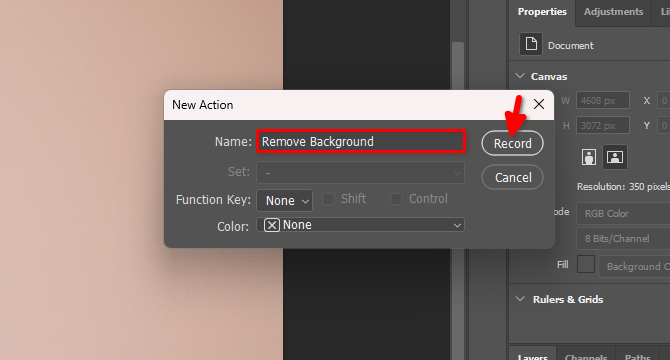
Digitare il nome della nuova azione, ad esempio Remove Background e fare clic su Record:
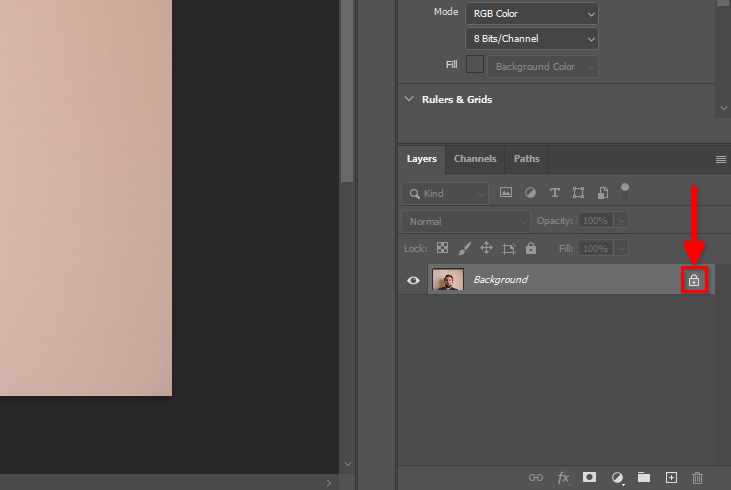
Nella scheda Layers, trovare il simbolo del lucchetto e fare clic su di esso:
Successivamente, fare clic sul pulsante Remove background nel pannello fluttuante:
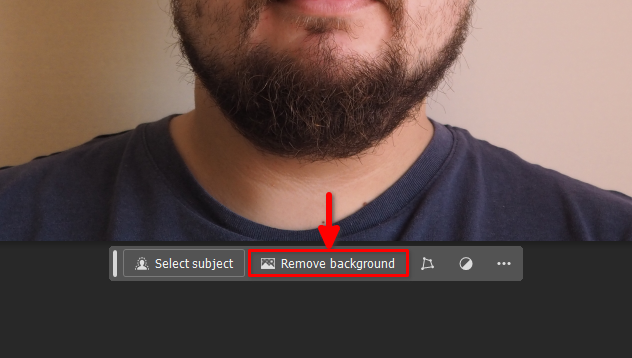
Fare clic con il tasto destro del mouse su Layer 0 e selezionare Flatten Image:
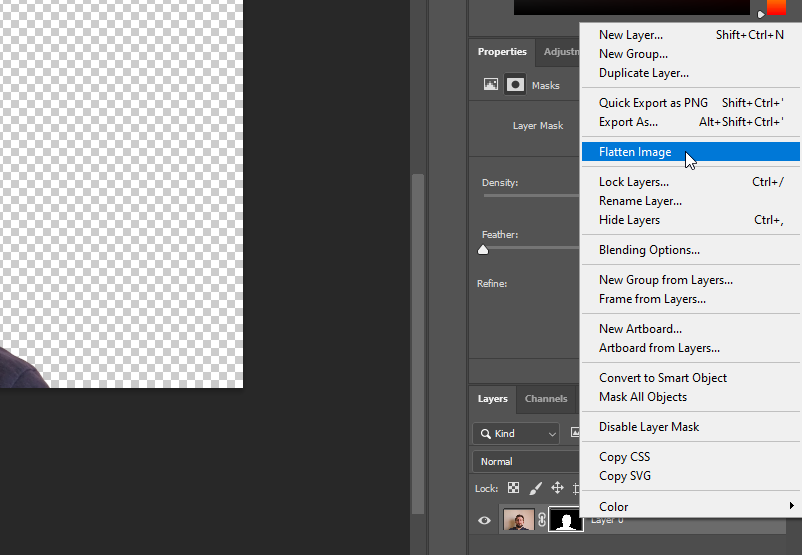
Tutte le nostre azioni sono state registrate. Fermiamo questo processo:
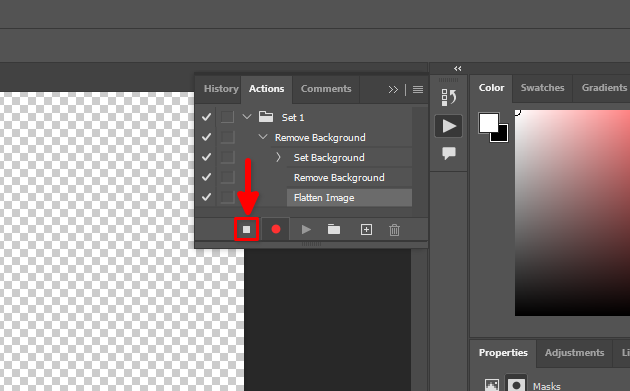
Ora è possibile chiudere il file aperto senza salvare le modifiche e selezionare File >> Scripts >> Image Processor…
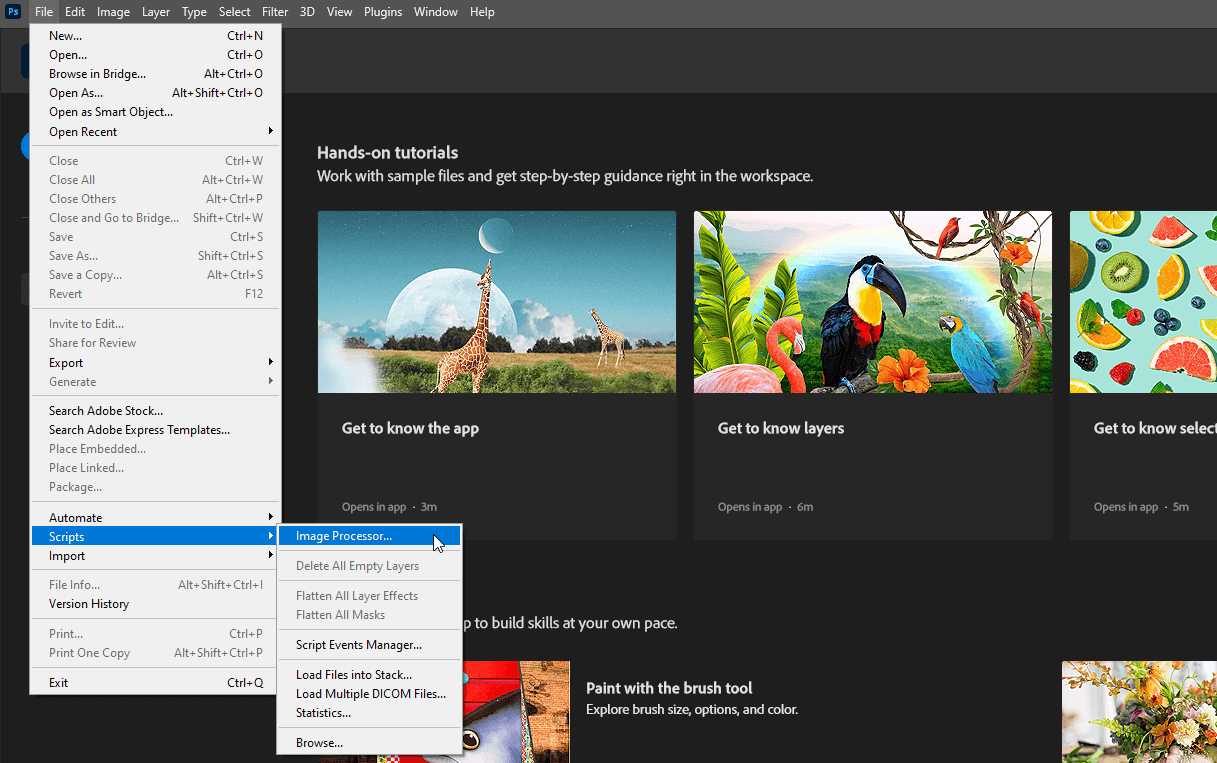
Selezionare le directory di input e output, scegliere l'azione Remove Background creata al punto 4 e fare clic sul pulsante Run:
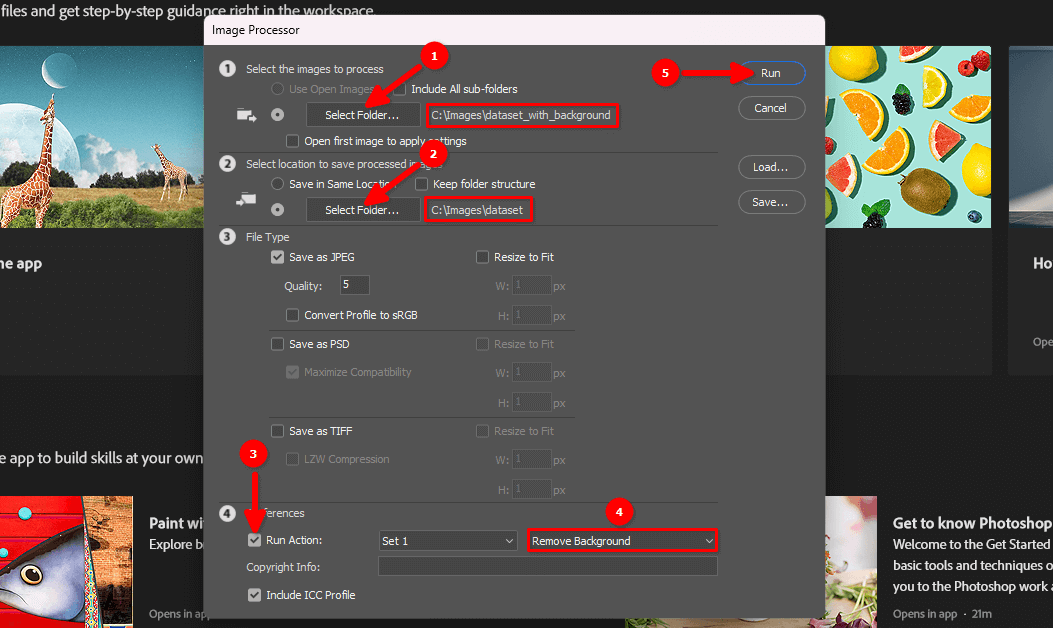
Si prega di essere pazienti. Adobe Photoshop aprirà tutte le immagini nella directory selezionata, ripeterà le azioni registrate (disattivazione del blocco dei livelli, eliminazione dello sfondo, appiattimento dell'immagine) e le salverà in un'altra directory selezionata. Questo processo può richiedere un paio di minuti, a seconda del numero di immagini.

Al termine del processo, è possibile passare alla fase successiva.
Caricare sul server
Per caricare la directory dataset sul server remoto, utilizzare una delle seguenti guide (adatte al sistema operativo del PC). Ad esempio, posizionatela nella home directory dell'utente predefinito, /home/usergpu:
Pre-installazione
Aggiornare i pacchetti di sistema esistenti:
sudo apt update && sudo apt -y upgradeInstallare due pacchetti aggiuntivi:
sudo apt install -y python3-tk python3.10-venvInstalliamo il CUDA® Toolkit versione 11.8. Scarichiamo il file pin specifico:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinIl comando seguente colloca il file scaricato nella directory di sistema, controllata dal gestore di pacchetti apt:
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600Il prossimo passo è scaricare il repository principale di CUDA:
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debDopodiché, procedere con l'installazione del pacchetto utilizzando l'utility standard dpkg:
sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debCopiare il portachiavi GPG nella directory di sistema. In questo modo sarà disponibile per l'uso da parte delle utility del sistema operativo, compreso il gestore di pacchetti apt:
sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/Aggiornare i repository della cache del sistema:
sudo apt-get updateInstallare il toolkit CUDA® utilizzando apt:
sudo apt-get -y install cudaAggiungere CUDA® al PATH. Aprire la configurazione della shell bash:
nano ~/.bashrcAggiungere le seguenti righe alla fine del file:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}Salvare il file e riavviare il server:
sudo shutdown -r nowInstallare l'allenatore
Copiare il repository del progetto Kohya sul server:
git clone https://github.com/bmaltais/kohya_ss.gitAprire la cartella scaricata:
cd kohya_ssRendere eseguibile lo script di setup:
chmod +x ./setup.shEseguire lo script:
./setup.shVerrà visualizzato un messaggio di avviso dall'utilità di accelerazione. Risolviamo il problema. Attivare l'ambiente virtuale del progetto:
source venv/bin/activateInstallare il pacchetto mancante:
pip install scipyE configurare manualmente l'utilità di accelerazione:
accelerate configFare attenzione, perché l'attivazione di un numero dispari di CPU causerà un errore. Ad esempio, se ho 5 GPU, solo 4 possono essere utilizzate con questo software. In caso contrario, si verificherà un errore all'avvio del processo. È possibile verificare immediatamente la nuova configurazione dell'utilità richiamando un test predefinito:
accelerate testSe tutto è a posto, si riceverà un messaggio come questo:
Test is a success! You are ready for your distributed training!
deactivateOra è possibile avviare il server pubblico del trainer con la GUI di Gradio e la semplice autenticazione con login/password (cambiare l'utente/password con la propria):
./gui.sh --share --username user --password passwordRiceverete due stringhe:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://.gradio.live
Aprire il browser web e inserire l'URL pubblico nella barra degli indirizzi. Digitare il nome utente e la password negli appositi campi, quindi fare clic su Login:
Preparare il set di dati
Iniziare creando una nuova cartella in cui memorizzare il modello LoRA addestrato:
mkdir /home/usergpu/myloramodelAprire le seguenti schede: Utilities >> Captioning >> BLIP captioning. Riempire gli spazi vuoti come mostrato nell'immagine e fare clic su Caption images:
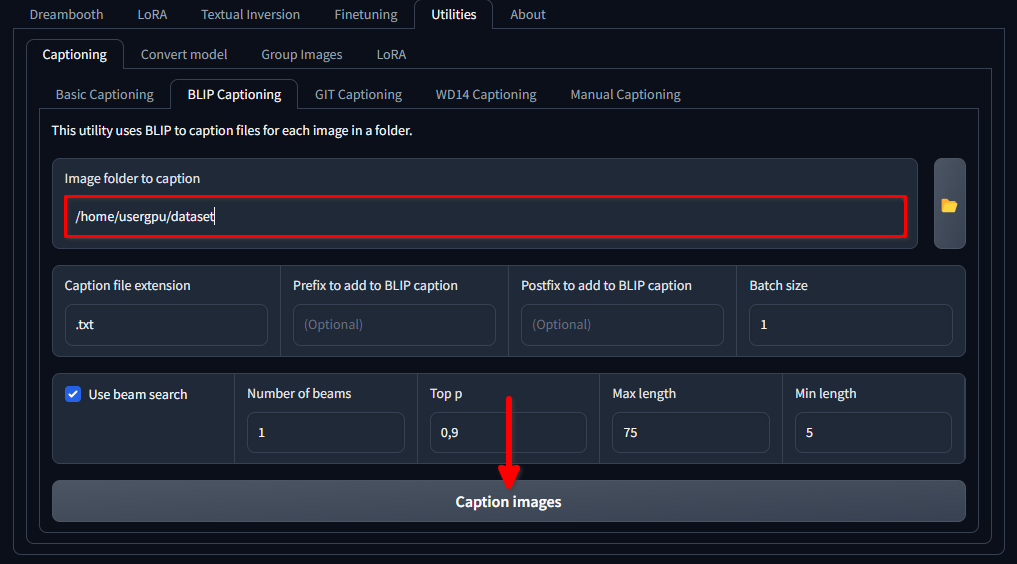
Trainer scaricherà ed eseguirà un modello di rete neurale specifico (1,6 Gb) che crea messaggi di testo per ogni file di immagine nella directory selezionata. L'esecuzione avviene su una singola GPU e richiede circa un minuto.
Passare alla scheda LoRA >> Tools >> Dataset preparation >> Dreambooth/LoRA folder preparation, riempire gli spazi vuoti e premere in sequenza Prepare training data e Copy info to Folders Tab:
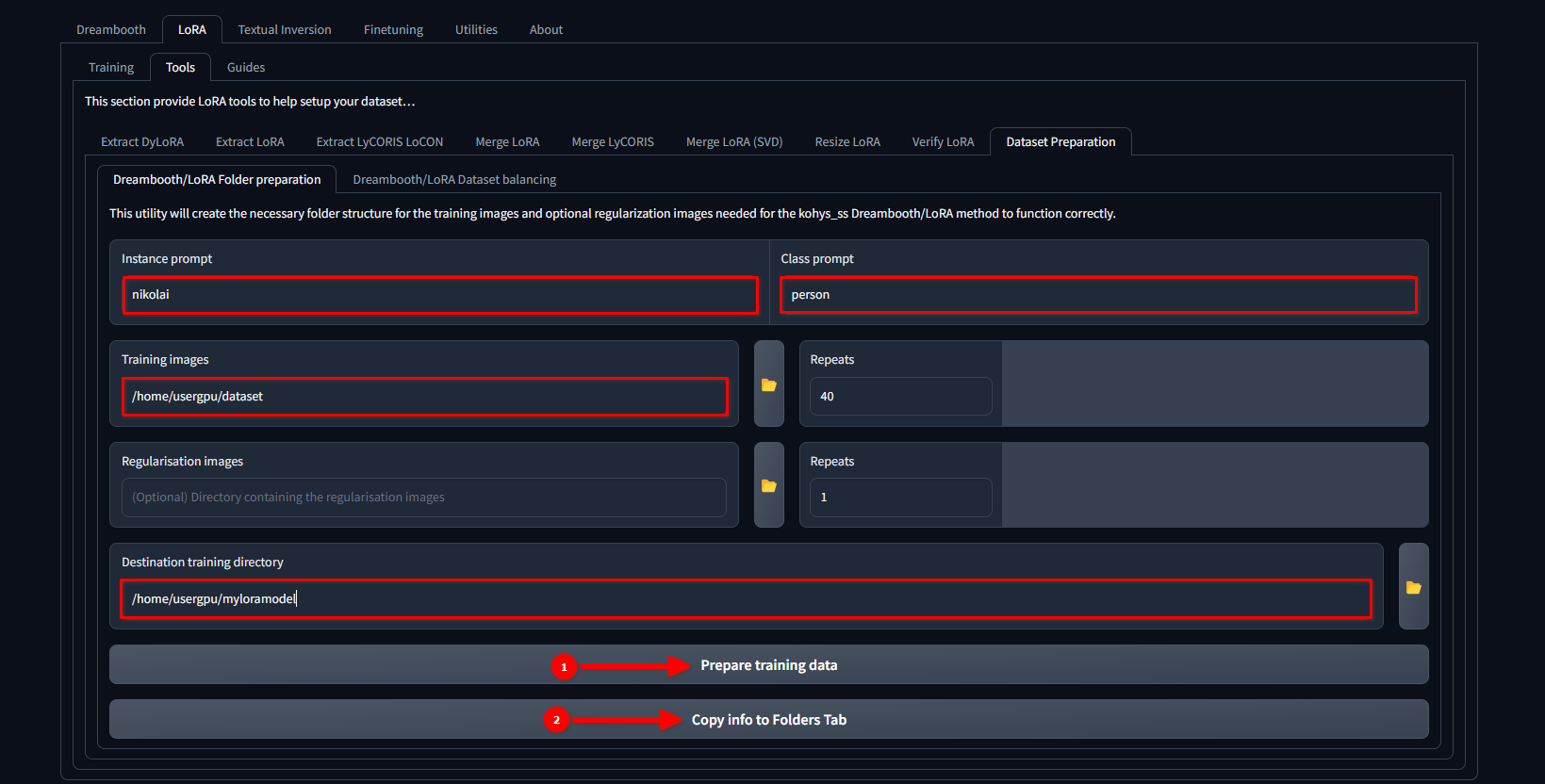
In questo esempio, utilizziamo il nome nikolai come Instance prompt e "persona" come Class prompt. Impostiamo anche /home/usergpu/dataset come Training Images e /home/usergpu/myloramodel come Destination training directory.
Passate nuovamente alla scheda LoRA >> Training >> Folders. Assicurarsi che Image folder, Output folder e Logging folder siano compilati correttamente. Se lo si desidera, è possibile modificare Model output name con il proprio nome. Infine, fare clic sul pulsante Start training:
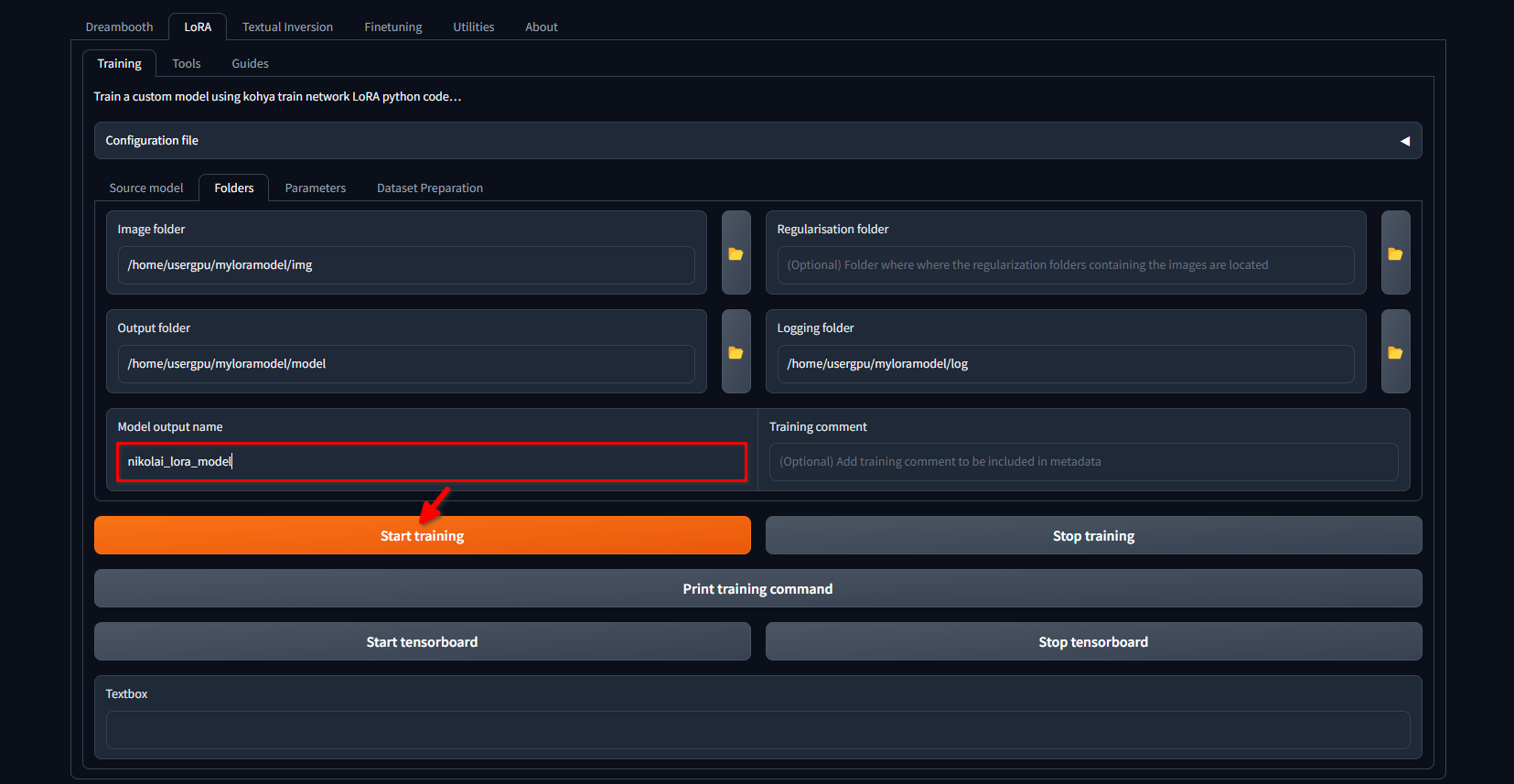
Il sistema inizierà a scaricare altri file e modelli (~10 GB). Dopodiché, inizierà il processo di addestramento. A seconda della quantità di immagini e delle impostazioni applicate, il processo può durare diverse ore. Una Volta™ completato l'addestramento, è possibile scaricare la directory /home/usergpu/myloramodel sul computer per un uso futuro.
Prova di LoRA
Abbiamo preparato alcuni articoli su Stable Diffusion e i suoi fork. Potete provare a installare Easy Diffusion con la nostra guida Easy Diffusion UI. Dopo che il sistema è stato installato e funziona, è possibile caricare il modello LoRA in formato SafeTensors direttamente su /home/usergpu/easy-diffusion/models/lora
Aggiornare la pagina web di Easy diffusion e selezionare il modello dall'elenco a discesa:
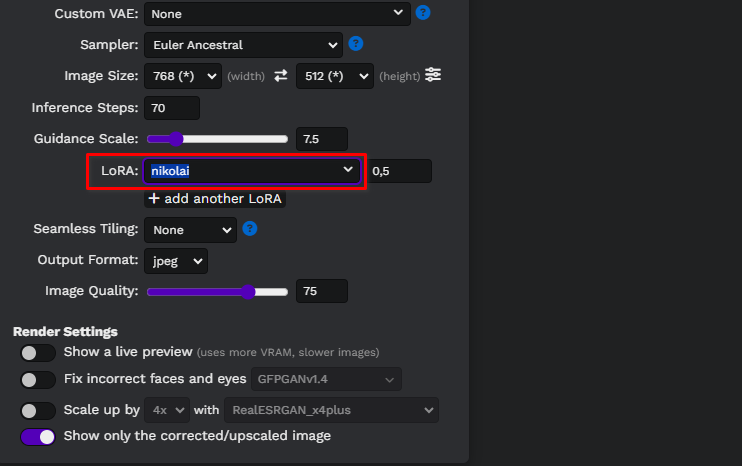
Scriviamo un semplice prompt, portrait of <nikolai> wearing a cowboy hat, e generiamo le prime immagini. In questo caso, abbiamo utilizzato un modello personalizzato di Diffusione stabile scaricato da civitai.com: Realistic Vision v6.0 B1:
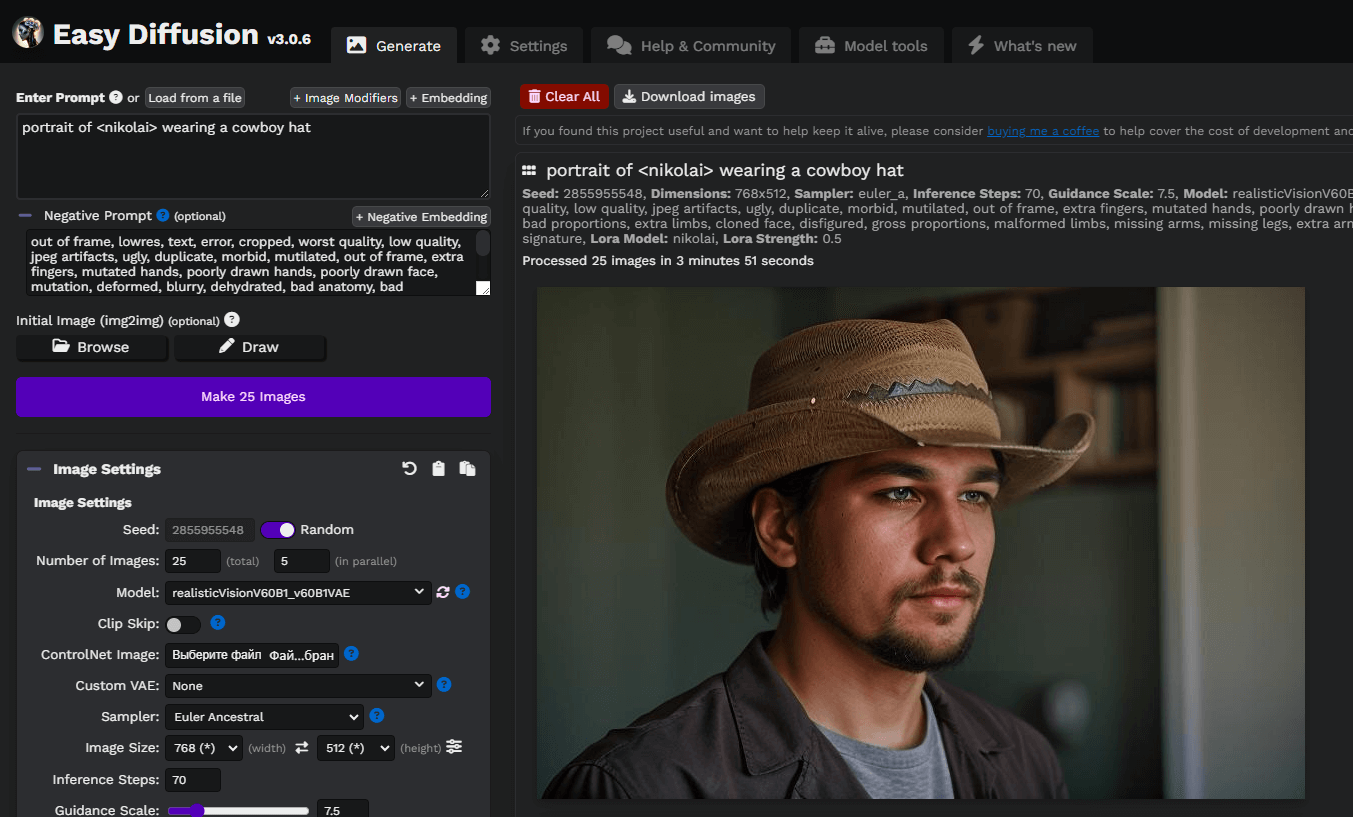
È possibile sperimentare con prompt e modelli basati su Stable Diffusion per ottenere risultati migliori. Buon divertimento!
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 21.01.2025




