





Costruttore di app AI a basso codice Langflow
Negli ultimi anni lo sviluppo del software si è evoluto notevolmente. I programmatori moderni hanno ora accesso a centinaia di linguaggi e framework di programmazione. Oltre ai tradizionali approcci imperativi e dichiarativi, sta emergendo un nuovo ed entusiasmante metodo per creare applicazioni. Questo approccio innovativo sfrutta la potenza delle reti neurali, aprendo agli sviluppatori fantastiche possibilità.
Le persone si sono abituate agli assistenti AI negli IDE che aiutano con l'autocompletamento del codice e alle moderne reti neurali che generano facilmente codice per semplici giochi in Python. Tuttavia, stanno emergendo nuovi strumenti ibridi che potrebbero rivoluzionare il panorama dello sviluppo. Uno di questi strumenti è Langflow.
Langflow ha molteplici scopi. Per gli sviluppatori professionisti, offre un migliore controllo su sistemi complessi come le reti neurali. Per coloro che non hanno familiarità con la programmazione, consente di creare applicazioni semplici ma pratiche. Questi obiettivi sono raggiunti con mezzi diversi, che analizzeremo in dettaglio.
Reti neurali
Il concetto di rete neurale può essere semplificato per gli utenti. Immaginate una scatola nera che riceve dati di input e parametri che influenzano il risultato finale. Questa scatola elabora i dati in ingresso utilizzando algoritmi complessi, spesso definiti "magici", e produce dati in uscita che possono essere presentati all'utente.
Il funzionamento interno di questa scatola nera varia in base al progetto della rete neurale e ai dati di addestramento. È fondamentale capire che gli sviluppatori e gli utenti non possono mai ottenere risultati certi al 100%. A differenza della programmazione tradizionale, dove 2 + 2 è sempre uguale a 4, una rete neurale potrebbe dare una risposta con una certezza del 99%, mantenendo sempre un margine di errore.
Il controllo sul processo di "pensiero" di una rete neurale è indiretto. Possiamo regolare solo alcuni parametri, come la "temperatura". Questo parametro determina quanto la rete neurale possa essere creativa o vincolata nel suo approccio. Un valore basso di temperatura limita la rete a un approccio più formale e strutturato ai compiti e alle soluzioni. Al contrario, valori di temperatura elevati concedono alla rete una maggiore libertà, che può portare a fare affidamento su fatti meno affidabili o addirittura alla creazione di informazioni fittizie.
Questo esempio illustra come gli utenti possano influenzare il risultato finale. Per la programmazione tradizionale, questa incertezza rappresenta una sfida significativa: gli errori possono comparire inaspettatamente e i risultati specifici diventano imprevedibili. Tuttavia, questa imprevedibilità è un problema principalmente dei computer, non degli esseri umani che possono adattarsi e interpretare risultati diversi.
Se l'output di una rete neurale è destinato a un essere umano, la formulazione specifica utilizzata per descriverlo è generalmente meno importante. Dato il contesto, le persone possono interpretare correttamente i vari risultati dal punto di vista della macchina. Mentre concetti come "valore positivo", "risultato raggiunto" o "decisione positiva" possono avere più o meno lo stesso significato per una persona, la programmazione tradizionale avrebbe difficoltà a gestire questa flessibilità. Dovrebbe tenere conto di tutte le possibili varianti di risposta, il che è quasi impossibile.
D'altra parte, se l'ulteriore elaborazione viene affidata a un'altra rete neurale, questa può comprendere ed elaborare correttamente il risultato ottenuto. Su questa base, può formulare le proprie conclusioni con un certo grado di sicurezza, come già detto.
Codice basso
La maggior parte dei linguaggi di programmazione prevede la scrittura di codice. I programmatori creano la logica di ogni parte di un'applicazione nella loro mente, quindi la descrivono utilizzando espressioni specifiche del linguaggio. Questo processo forma un algoritmo: una chiara sequenza di azioni che porta a un risultato specifico e predeterminato. È un compito complesso che richiede un notevole sforzo mentale e una profonda conoscenza delle capacità del linguaggio.
Tuttavia, non è necessario reinventare la ruota. Molti problemi affrontati dagli sviluppatori moderni sono già stati risolti in vari modi. Su StackOverflow si possono trovare spesso frammenti di codice pertinenti. La programmazione moderna può essere paragonata all'assemblaggio di un intero con parti di diversi set di costruzione. Il sistema Lego offre un modello di successo, avendo standardizzato diversi set di pezzi per garantire la compatibilità.
Il metodo di programmazione low-code segue un principio simile. I vari pezzi di codice vengono modificati per adattarsi perfettamente l'uno all'altro e vengono presentati agli sviluppatori come blocchi già pronti. Ogni blocco può avere ingressi e uscite di dati. La documentazione specifica il compito che ogni tipo di blocco risolve e il formato in cui accetta o emette i dati.
Collegando questi blocchi in una sequenza specifica, gli sviluppatori possono formare l'algoritmo di un'applicazione e visualizzarne chiaramente la logica operativa. Forse l'esempio più noto di questo metodo di programmazione è il metodo della grafica a tartaruga, comunemente utilizzato in ambito didattico per introdurre i concetti di programmazione e sviluppare il pensiero algoritmico.
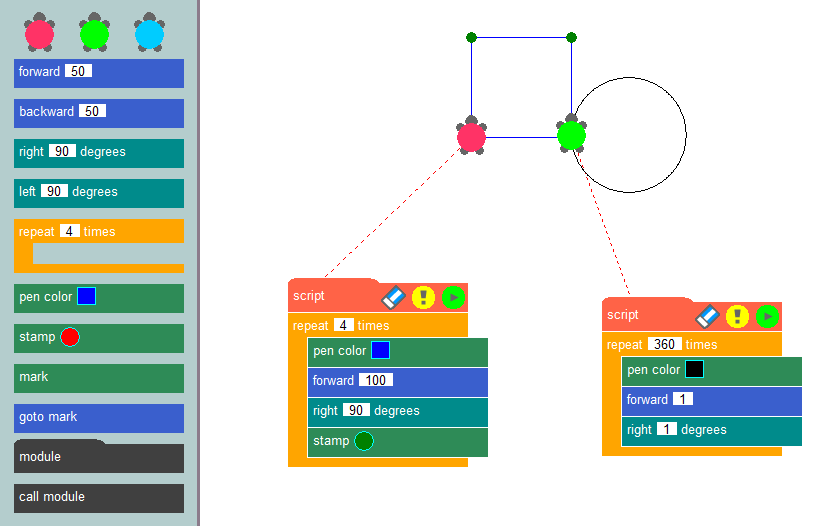
L'essenza di questo metodo è semplice: disegnare immagini sullo schermo utilizzando una tartaruga virtuale che lascia una scia mentre striscia sulla tela. Utilizzando blocchi già pronti, come lo spostamento di un determinato numero di pixel, la rotazione ad angoli specifici o il sollevamento e l'abbassamento della penna, gli sviluppatori possono creare programmi che disegnano le immagini desiderate. La creazione di applicazioni utilizzando un costruttore low-code è simile alla grafica delle tartarughe, ma consente agli utenti di risolvere un'ampia gamma di problemi, non solo il disegno su una tela.
Questo metodo è stato implementato al meglio nello strumento di programmazione Node-RED di IBM. È stato sviluppato come mezzo universale per garantire il funzionamento congiunto di diversi dispositivi, servizi online e API. L'equivalente dei frammenti di codice erano i nodi della libreria standard (palette).

Le capacità di Node-RED possono essere ampliate installando componenti aggiuntivi o creando nodi personalizzati che eseguono azioni specifiche sui dati. Gli sviluppatori posizionano i nodi della tavolozza sul desktop e creano relazioni tra di essi. Questo processo crea la logica dell'applicazione, mentre la visualizzazione aiuta a mantenere la chiarezza.
Aggiungendo le reti neurali a questo concetto si ottiene un sistema intrigante. Invece di elaborare i dati con formule matematiche specifiche, è possibile inserirli in una rete neurale e specificare l'output desiderato. Anche se i dati in ingresso possono variare leggermente ogni Volta™, i risultati rimangono adatti all'interpretazione da parte dell'uomo o di altre reti neurali.
Generazione aumentata di recupero (RAG)
L'accuratezza dei dati nei modelli linguistici di grandi dimensioni è un problema urgente. Questi modelli si basano esclusivamente sulla conoscenza acquisita durante l'addestramento, che dipende dalla rilevanza dei set di dati utilizzati. Di conseguenza, i modelli linguistici di grandi dimensioni possono non avere sufficienti dati rilevanti, portando potenzialmente a risultati errati.
Per risolvere questo problema, sono necessari metodi di aggiornamento dei dati. Consentire alle reti neurali di estrarre il contesto da fonti aggiuntive, come i siti web, può migliorare significativamente la qualità delle risposte. È proprio così che funziona la RAG (Retrieval-Augmented Generation). I dati aggiuntivi vengono convertiti in rappresentazioni vettoriali e memorizzati in un database.
In pratica, i modelli di rete neurale possono convertire le richieste degli utenti in rappresentazioni vettoriali e confrontarle con quelle memorizzate nel database. Quando vengono trovati vettori simili, i dati vengono estratti e utilizzati per formare una risposta. I database vettoriali sono sufficientemente veloci per supportare questo schema in tempo reale.
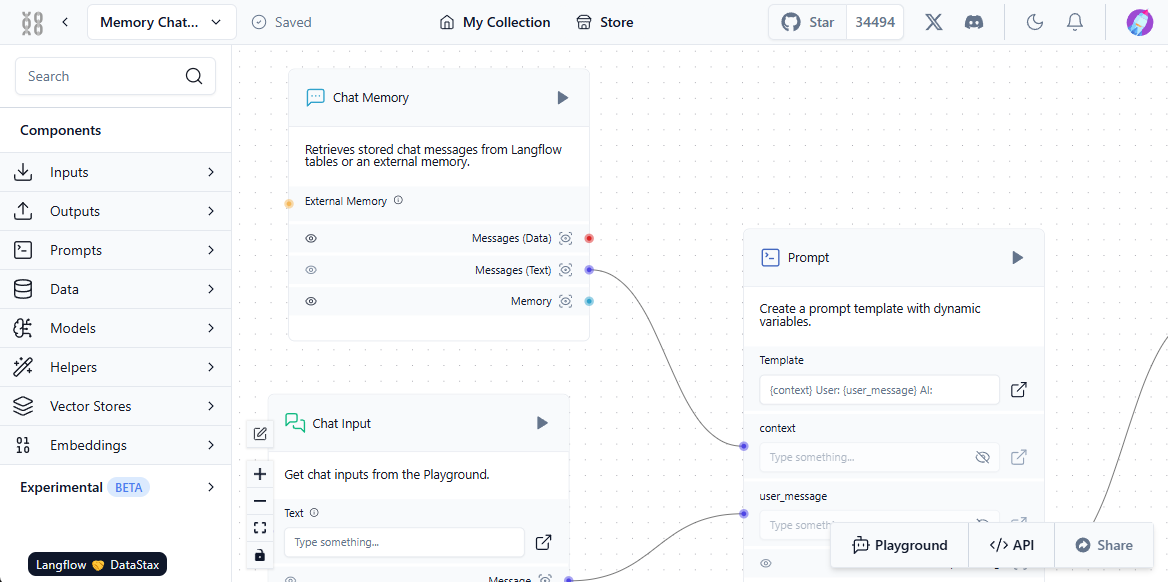
Affinché questo sistema funzioni correttamente, è necessario stabilire un'interazione tra l'utente, il modello di rete neurale, le fonti di dati esterne e il database vettoriale. Langflow semplifica questa configurazione grazie alla sua componente visiva: gli utenti costruiscono semplicemente dei blocchi standard e li "collegano", creando un percorso per il flusso dei dati.
Il primo passo è quello di popolare il database vettoriale con le fonti pertinenti. Queste possono includere file da un computer locale o pagine web da Internet. Ecco un semplice esempio di caricamento dei dati nel database:
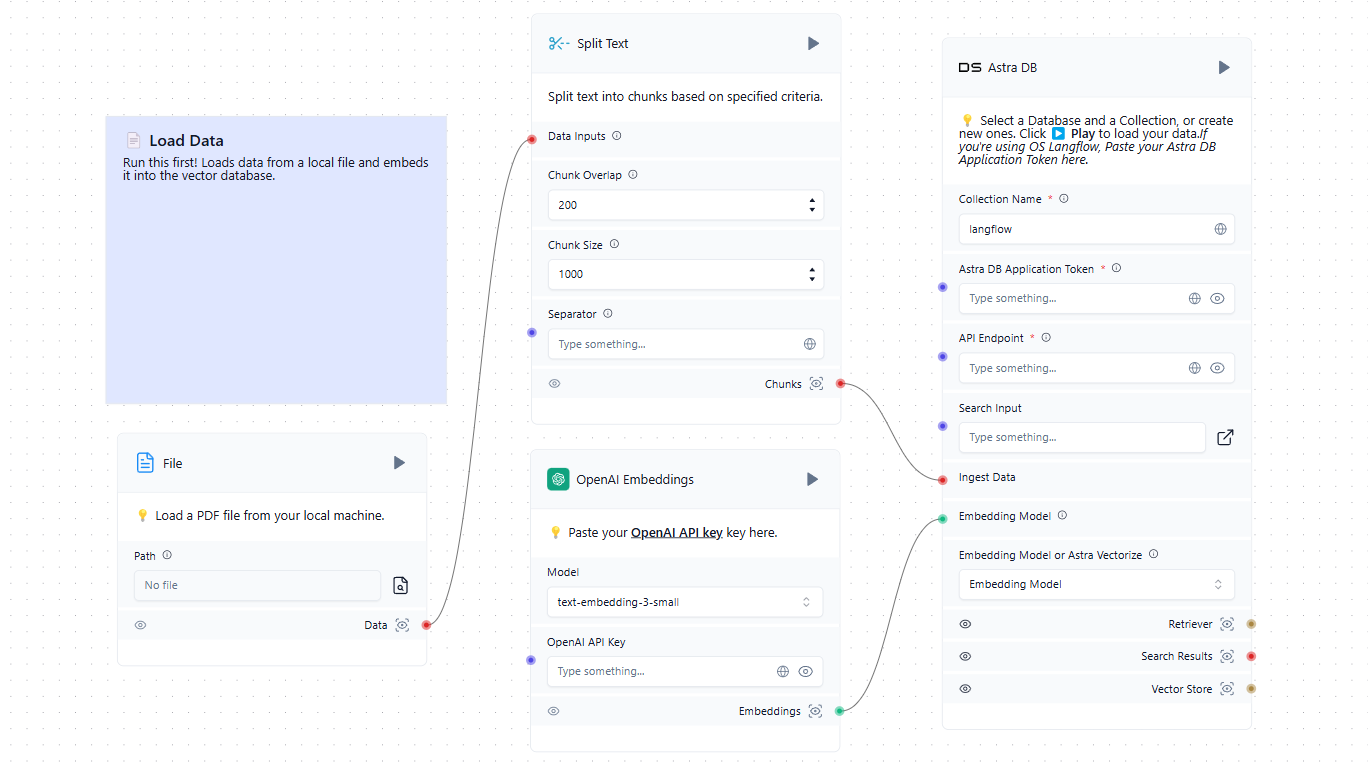
Ora che abbiamo un database vettoriale oltre all'LLM addestrato, possiamo incorporarlo nello schema generale. Quando un utente invia una richiesta nella chat, il sistema forma contemporaneamente un prompt e interroga il database dei vettori. Se vengono trovati vettori simili, i dati estratti vengono analizzati e aggiunti come contesto alla richiesta formata. Il sistema invia quindi una richiesta alla rete neurale e invia la risposta ricevuta all'utente nella chat.
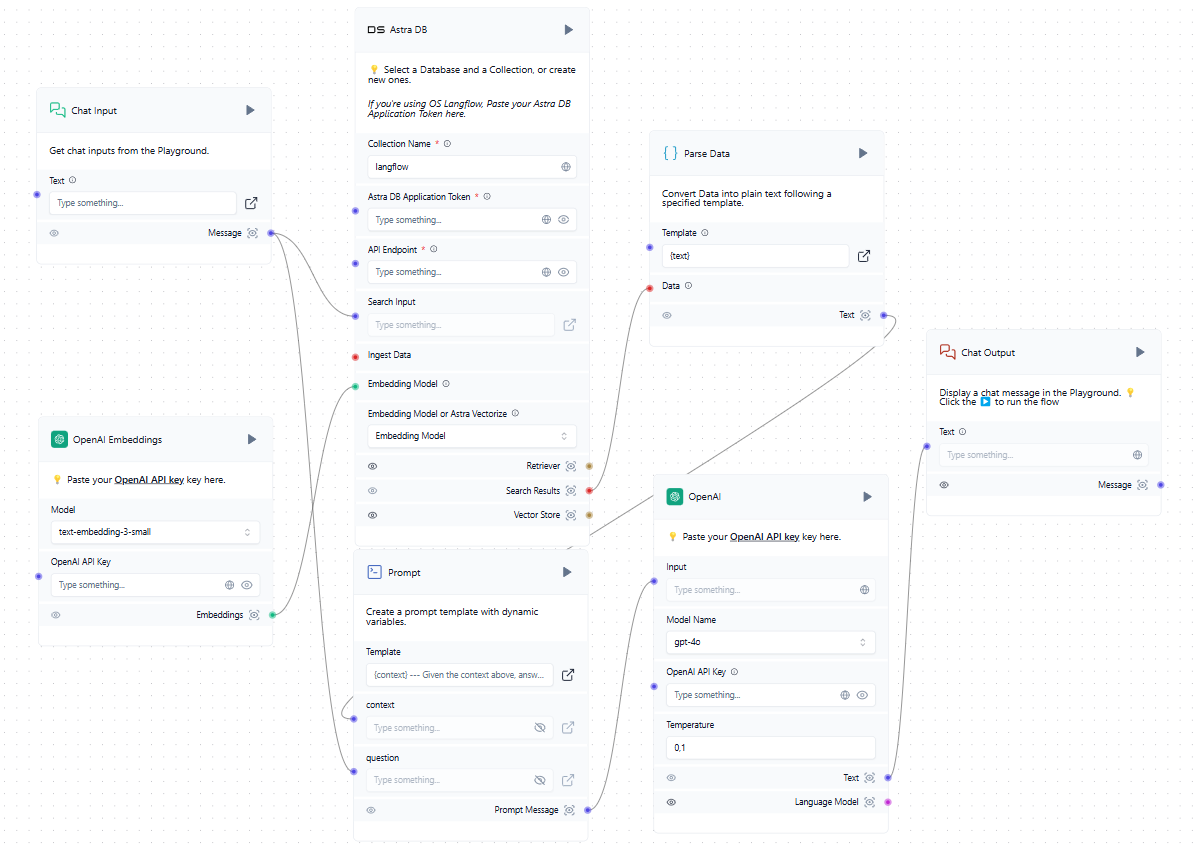
Sebbene l'esempio citi servizi cloud come OpenAI e AstraDB, è possibile utilizzare qualsiasi servizio compatibile, compresi quelli distribuiti localmente sui server LeaderGPU. Se non riuscite a trovare l'integrazione di cui avete bisogno nell'elenco dei blocchi disponibili, potete scriverla voi stessi o aggiungerne una creata da qualcun altro.
Avvio rapido
Preparazione del sistema
Il modo più semplice per distribuire Langflow è all'interno di un contenitore Docker. Per configurare il server, iniziare con l'installazione di Docker Engine. Quindi, aggiornate sia la cache dei pacchetti che i pacchetti alle loro ultime versioni:
sudo apt update && sudo apt -y upgradeInstallare i pacchetti aggiuntivi richiesti da Docker:
sudo apt -y install apt-transport-https ca-certificates curl software-properties-commonScaricare la chiave GPG per aggiungere il repository ufficiale di Docker:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgAggiungere il repository ad APT utilizzando la chiave scaricata e installata in precedenza:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullAggiornare l'elenco dei pacchetti:
sudo apt updatePer assicurarsi che Docker venga installato dal nuovo repository aggiunto e non da quello di sistema, è possibile eseguire il seguente comando:
apt-cache policy docker-ceInstalla motore Docker:
sudo apt install docker-ceVerificare che Docker sia stato installato correttamente e che il demone corrispondente sia in esecuzione e nello stato active (running):
sudo systemctl status docker● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running) since Mon 2024-11-18 08:26:35 UTC; 3h 27min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1842 (dockerd)
Tasks: 29
Memory: 1.8G
CPU: 3min 15.715s
CGroup: /system.slice/docker.service
Costruire ed eseguire
Tutto è pronto per costruire ed eseguire un contenitore Docker con Langflow. Tuttavia, c'è un'avvertenza: al momento della stesura di questa guida, l'ultima versione (taggata v1.1.0) presenta un errore e non si avvia. Per evitare questo problema, useremo la versione precedente, v1.0.19.post2, che funziona perfettamente subito dopo il download.
L'approccio più semplice è quello di scaricare il repository del progetto da GitHub:
git clone https://github.com/langflow-ai/langflowNavigare nella cartella contenente la configurazione di deployment di esempio:
cd langflow/docker_exampleOra è necessario fare due cose. Primo, cambiare il tag release, in modo da creare una versione funzionante (al momento della stesura di queste istruzioni). In secondo luogo, aggiungere una semplice autorizzazione, in modo che nessuno possa usare il sistema senza conoscere login e password.
Aprire il file di configurazione:
sudo nano docker-compose.ymlinvece della riga seguente:
image: langflowai/langflow:latestspecificare la versione invece del tag latest:
image: langflowai/langflow:v1.0.19.post2È inoltre necessario aggiungere tre variabili alla sezione environment:
- LANGFLOW_AUTO_LOGIN=false
- LANGFLOW_SUPERUSER=admin
- LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordLa prima variabile disabilita l'accesso all'interfaccia web senza autorizzazione. La seconda aggiunge il nome utente che riceverà i diritti di amministratore del sistema. La terza aggiunge la password corrispondente.
Se si intende memorizzare il file docker-compose.yml in un sistema di controllo della versione, evitare di scrivere la password direttamente in questo file. Creare invece un file separato con estensione .env nella stessa directory e memorizzare lì il valore della variabile.
LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordNel file docker-compose.yml è ora possibile fare riferimento a una variabile invece di specificare direttamente la password:
LANGFLOW_SUPERUSER_PASSWORD=${LANGFLOW_SUPERUSER_PASSWORD}Per evitare di esporre accidentalmente il file *.env su GitHub, ricordarsi di aggiungerlo a .gitignore. In questo modo la password rimarrà ragionevolmente al sicuro da accessi indesiderati.
Ora non resta che costruire il nostro contenitore ed eseguirlo:
sudo docker compose upAprire la pagina web all'indirizzo http://[LeaderGPU_IP_address]:7860 e si vedrà il modulo di autorizzazione:
Una Volta™ inseriti login e password, il sistema concede l'accesso all'interfaccia web dove è possibile creare le proprie applicazioni. Per una guida più approfondita, si consiglia di consultare la documentazione ufficiale. Essa fornisce dettagli su diverse variabili d'ambiente che consentono una facile personalizzazione del sistema in base alle proprie esigenze.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 22.01.2025




