





PrivateGPT: AI per i documenti

I modelli linguistici di grandi dimensioni si sono evoluti notevolmente negli ultimi anni e sono diventati strumenti efficaci per molte attività. L'unico problema del loro utilizzo è che la maggior parte dei prodotti basati su questi modelli utilizza servizi già pronti di aziende terze. Questo utilizzo ha il potenziale di far trapelare dati sensibili, per cui molte aziende evitano di caricare documenti interni su servizi LLM pubblici.
Un progetto come PrivateGPT potrebbe essere una soluzione. Inizialmente è stato progettato per un uso completamente locale. Il suo punto di forza è che potete inviare vari documenti come input, e la rete neurale li leggerà per voi e fornirà i propri commenti in risposta alle vostre richieste. Ad esempio, è possibile "dargli in pasto" testi di grandi dimensioni e chiedergli di trarre delle conclusioni in base alle richieste dell'utente. In questo modo è possibile risparmiare notevolmente tempo nella correzione delle bozze.
Questo è particolarmente vero per i settori professionali come la medicina. Ad esempio, un medico può fare una diagnosi e chiedere alla rete neurale di confermarla sulla base della serie di documenti caricati. Ciò consente di ottenere un ulteriore parere indipendente, riducendo così il numero di errori medici. Poiché le richieste e i documenti non lasciano il server, si può essere certi che i dati ricevuti non appaiano di dominio pubblico.
Oggi vi mostreremo come implementare una rete neurale sui server dedicati LeaderGPU con il sistema operativo Ubuntu 22.04 LTS in soli 20 minuti.
Preparazione del sistema
Iniziate aggiornando i pacchetti all'ultima versione:
sudo apt update && sudo apt -y upgradeA questo punto, installare altri pacchetti, librerie e il driver grafico NVIDIA®. Tutti questi elementi sono necessari per compilare il software ed eseguirlo sulla GPU:
sudo apt -y install build-essential git gcc cmake make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev lzma liblzma-dev libbz2-devInstallazione di CUDA® 12.4
Oltre al driver, è necessario installare il toolkit NVIDIA® CUDA®. Queste istruzioni sono state testate su CUDA® 12.4, ma tutto dovrebbe funzionare anche su CUDA® 12.2. Tuttavia, tenete presente che dovrete indicare la versione installata quando specificate il percorso dei file eseguibili.
Eseguire il seguente comando in sequenza:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get update && sudo apt-get -y install cuda-toolkit-12-4Ulteriori informazioni sull'installazione di CUDA® sono disponibili nella nostra Knowledge Base. A questo punto, riavviare il server:
sudo shutdown -r nowinstallare PyEnv
È il momento di installare una semplice utility di controllo della versione di Python, chiamata PyEnv. Si tratta di un fork notevolmente migliorato del progetto simile per Ruby (rbenv), configurato per funzionare con Python. Può essere installata con uno script di una riga:
curl https://pyenv.run | bashOra, è necessario aggiungere alcune variabili alla fine del file di script, che viene eseguito al momento del login. Le prime tre righe sono responsabili del corretto funzionamento di PyEnv, mentre la quarta è necessaria per Poetry, che sarà installato in seguito:
nano .bashrcexport PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
export PATH="/home/usergpu/.local/bin:$PATH"Applicare le impostazioni effettuate:
source .bashrcInstallare la versione 3.11 di Python:
pyenv install 3.11Creare un ambiente virtuale per Python 3.11:
pyenv local 3.11Installazione della poesia
Il prossimo pezzo del puzzle è Poetry. Si tratta di un analogo di pip per la gestione delle dipendenze nei progetti Python. L'autore di Poetry era stanco di avere costantemente a che fare con diversi metodi di configurazione, come setup.cfg, requirements.txt, MANIFEST.ini e altri. Questo è stato il motore per lo sviluppo di un nuovo strumento che utilizza un file pyproject.toml, che memorizza tutte le informazioni di base su un progetto, non solo un elenco di dipendenze.
Installare la poesia:
curl -sSL https://install.python-poetry.org | python3 -Installazione di PrivateGPT
Ora che tutto è pronto, si può clonare il repository PrivateGPT:
git clone https://github.com/imartinez/privateGPTAndare al repository scaricato:
cd privateGPTEseguire l'installazione delle dipendenze utilizzando Poetry e abilitando i componenti aggiuntivi:
- ui - aggiunge un'interfaccia web di gestione basata su Gradio all'applicazione backend;
- embedding-huggingface - abilita il supporto per l'incorporazione dei modelli scaricati da HuggingFace;
- llms-llama-cpp - aggiunge il supporto per l'inferenza diretta dei modelli in formato GGUF;
- vector-stores-qdrant - aggiunge il database vettoriale qdrant.
poetry install --extras "ui embeddings-huggingface llms-llama-cpp vector-stores-qdrant"Impostare il token di accesso a Hugging Face. Per ulteriori informazioni, leggete questo articolo:
export HF_TOKEN="YOUR_HUGGING_FACE_ACCESS_TOKEN"Ora, eseguite lo script di installazione, che scaricherà automaticamente il modello e i pesi (Meta Llama 3.1 8B Instruct di default):
poetry run python scripts/setupIl comando seguente ricompila llms-llama-cpp separatamente per abilitare il supporto NVIDIA® CUDA®, al fine di scaricare i carichi di lavoro sulla GPU:
CUDACXX=/usr/local/cuda-12/bin/nvcc CMAKE_ARGS="-DGGML_CUDA=on -DCMAKE_CUDA_ARCHITECTURES=native" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir --force-reinstall --upgradeSe si ottiene un errore come nvcc fatal : Unsupported gpu architecture 'compute_' è sufficiente specificare l'architettura esatta della GPU in uso. Ad esempio: DCMAKE_CUDA_ARCHITECTURES=86 per NVIDIA® RTX™ 3090.
L'ultimo passo prima di iniziare è installare il supporto per le chiamate asincrone (async/await):
pip install asyncioEseguire PrivateGPT
Esegue PrivateGPT con un solo comando:
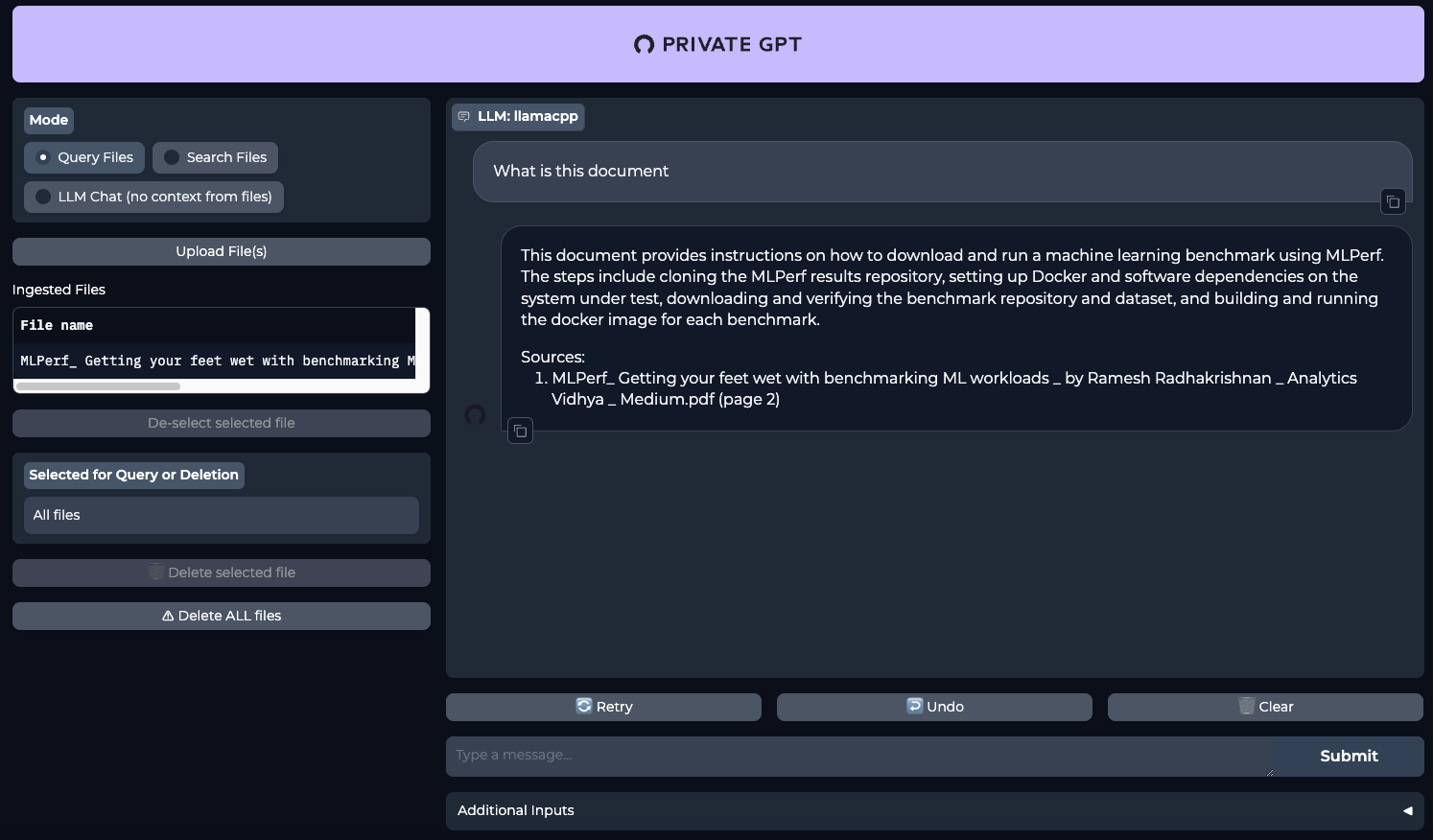
make runAprite il vostro browser web e andate alla pagina http://[LeaderGPU_server_IP_address]:8001
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




