





AudioCraft di MetaAI: creare musica per descrizione

Le moderne reti neurali generative stanno diventando sempre più intelligenti. Scrivono storie, dialogano con le persone e creano immagini ultra-realistiche. Ora possono produrre semplici brani musicali senza bisogno di artisti professionisti. Questo futuro è diventato realtà oggi. È previsto, poiché le armonie e i ritmi musicali sono radicati in principi matematici.
Meta ha dimostrato il suo impegno nel mondo del software open-source. Ha reso disponibili al pubblico tre modelli di reti neurali che consentono di creare suoni e musica a partire da descrizioni testuali:
- MusicGen - genera musica dal testo.
- AudioGen - genera audio dal testo.
- EnCodec - compressore audio neurale di alta qualità.
MusicGen è stato addestrato su 20.000 ore di musica. È possibile utilizzarlo localmente tramite i server dedicati di LeaderGPU come piattaforma.
Installazione standard
Aggiornare il repository della cache dei pacchetti:
sudo apt update && sudo apt -y upgradeInstallare il gestore di pacchetti Python, pip, e le librerie ffmpeg:
sudo apt -y install python3-pip ffmpegInstallare torch 2.0 o più recente usando pip:
pip install 'torch>=2.0'Il prossimo comando installa automaticamente audiocraft e tutte le dipendenze necessarie:
pip install -U audiocraftScriviamo una semplice applicazione Python, utilizzando il modello MusicGen pre-addestrato con 3,3B parametri:
nano generate.pyfrom audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained("facebook/musicgen-large")
model.set_generation_params(duration=30) # generate a 30 seconds sample.
descriptions = ["rock solo"]
wav = model.generate(descriptions) # generates sample.
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")Eseguire l'applicazione creata:
python3 generate.pyDopo qualche secondo, il file generato (0.wav) apparirà nella directory.
Caffè Vampir 3
Clonare un repository di progetto:
git clone https://github.com/CoffeeVampir3/audiocraft-webui.gitAprire la cartella clonata:
cd audiocraft-webuiEseguire il comando che prepara il sistema e installa tutti i pacchetti necessari:
pip install -r requirements.txtEseguire quindi il server Coffee Vampire 3 con il seguente comando:
python3 webui.pyCoffee Vampire 3 utilizza Flask come framework. Per impostazione predefinita, viene eseguito su localhost con la porta 5000. Se si desidera un accesso remoto, utilizzare la funzione di port forwarding nel proprio client SSH. Altrimenti, è possibile organizzare una connessione VPN al server.
Attenzione! Si tratta di un'azione potenzialmente pericolosa; utilizzatela a vostro rischio e pericolo:
nano webui.pyScorrere fino alla fine e sostituire socketio.run(app) con socketio.run(app, host=’0.0.0.0’, port=5000)
Salvare il file ed eseguire il server con il comando precedente. Questo permette di accedere al server da Internet senza alcuna autenticazione.
Non dimenticate disable AdBlock software, perché può bloccare il lettore musicale sul lato destro della pagina web. Si può iniziare inserendo il prompt e confermando con il pulsante Submit:
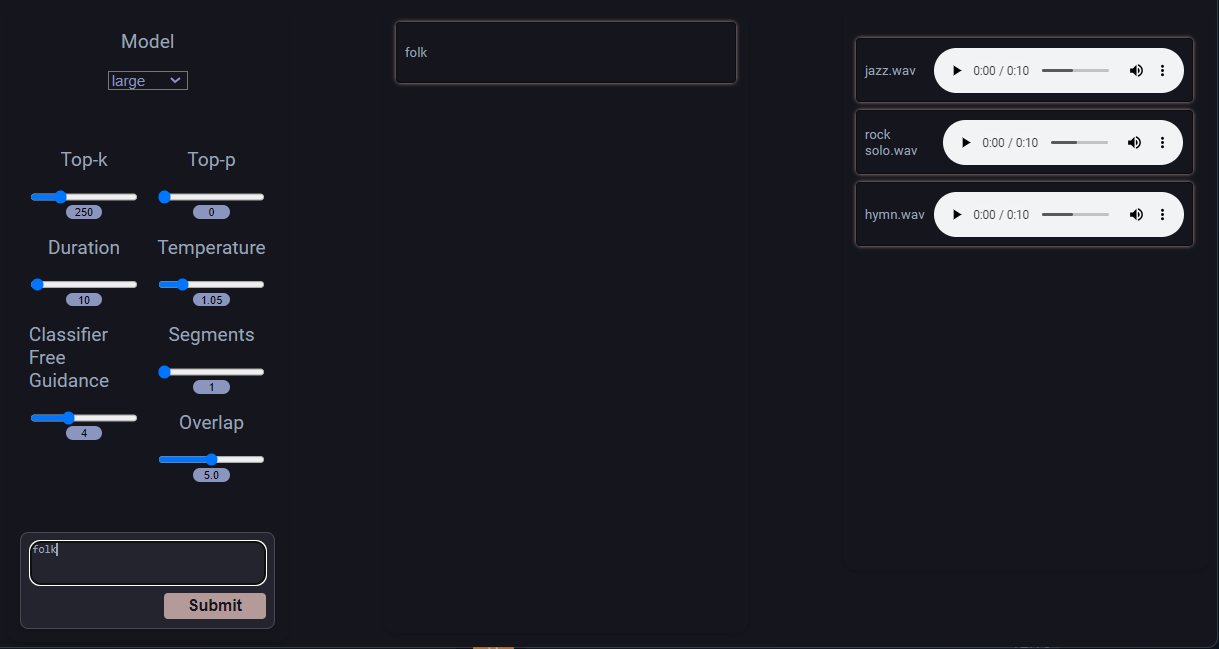
Generazione TTS WebUI
Passo 1. Driver
Aggiornare il repository della cache dei pacchetti:
sudo apt update && sudo apt -y upgradeInstallare i driver NVIDIA® utilizzando il programma di installazione automatica o la nostra guida Installare i driver NVIDIA® in Linux:
sudo ubuntu-drivers autoinstallRiavviare il server:
sudo shutdown -r nowPasso 2. Docker
Il passo successivo è l'installazione di Docker. Installiamo alcuni pacchetti che devono essere aggiunti al repository Docker:
sudo apt -y install apt-transport-https curl gnupg-agent ca-certificates software-properties-commonScaricare la chiave GPG di Docker e memorizzarla:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -Aggiungere il repository:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"Installare Docker CE (Community Edition) con la CLI e il runtime containerd:
sudo apt -y install docker-ce docker-ce-cli containerd.ioAggiungere l'utente corrente al gruppo docker:
sudo usermod -aG docker $USERApplicare le modifiche senza la procedura di logout e login:
newgrp dockerPasso 3. Passaggio della GPU
Abilitiamo il passthrough delle GPU NVIDIA® in Docker. Il comando seguente legge la versione corrente del sistema operativo nella variabile di distribuzione, che può essere utilizzata nel passaggio successivo:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)Scaricare la chiave GPG del repository NVIDIA® e memorizzarla:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -Scaricare l'elenco dei repository NVIDIA® e memorizzarlo per utilizzarlo nel gestore di pacchetti APT standard:
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listAggiornare il repository della cache dei pacchetti e installare il toolkit GPU Passthrough:
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkitRiavviare il demone Docker:
sudo systemctl restart dockerPasso 4. WebUI
Scaricate l'archivio del repository:
wget https://github.com/rsxdalv/tts-generation-webui/archive/refs/heads/main.zipScompattarlo:
unzip main.zipAprire la cartella del progetto:
cd tts-generation-webui-mainAvviare la costruzione dell'immagine:
docker build -t rsxdalv/tts-generation-webui .Eseguire il contenitore creato:
docker compose up -dOra è possibile aprire http://[server_ip]:7860, digitare il prompt, selezionare il modello necessario e fare clic sul pulsante Generate:
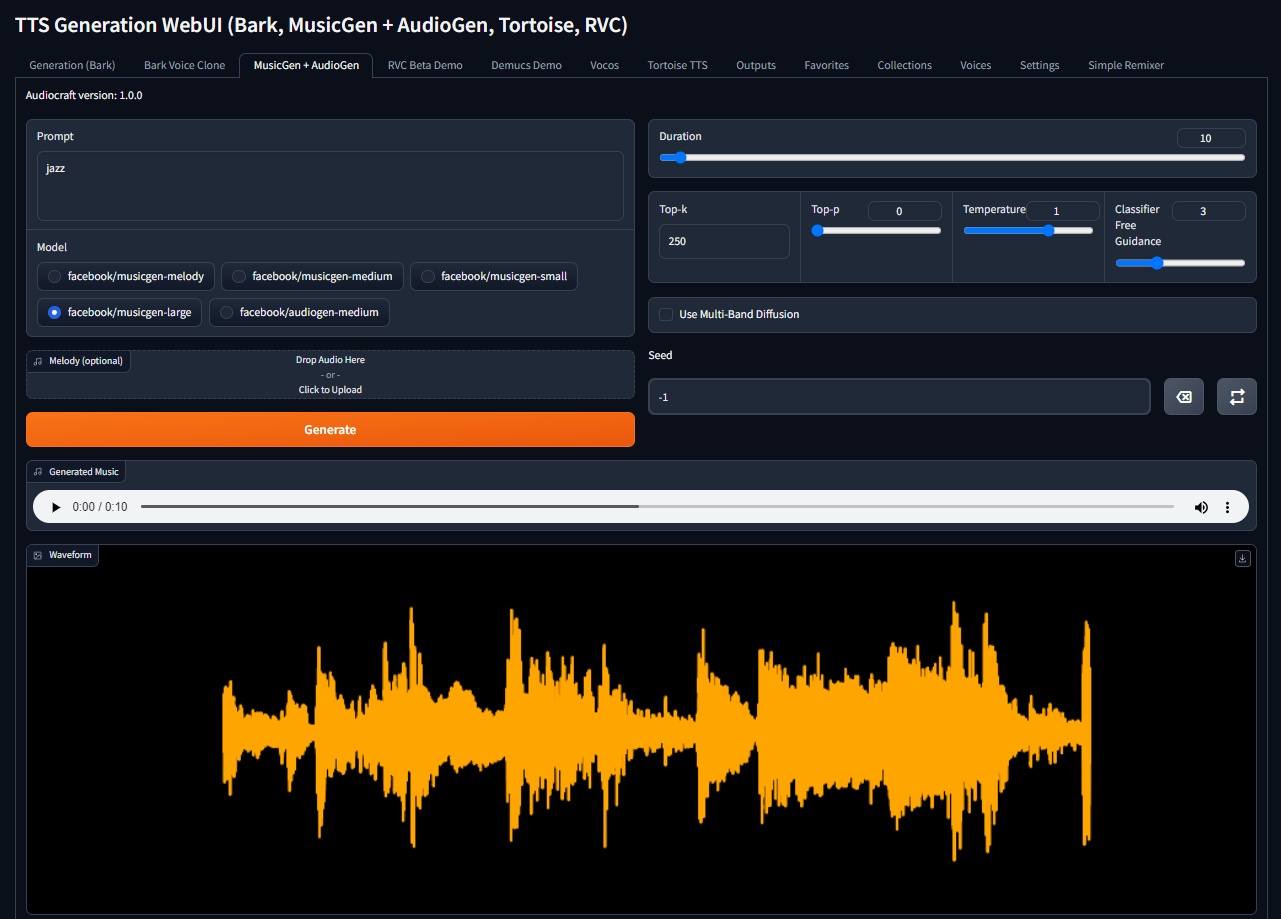
Il sistema scarica automaticamente il modello selezionato durante la prima generazione. Buon divertimento!
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 22.01.2025




