





DeepSeek-R1: il futuro dei LLM

Sebbene le reti neurali generative si siano sviluppate rapidamente, negli ultimi anni i loro progressi sono rimasti piuttosto costanti. La situazione è cambiata con l'arrivo di DeepSeek, una rete neurale cinese che non solo ha avuto un impatto sul mercato azionario, ma ha anche catturato l'attenzione di sviluppatori e ricercatori di tutto il mondo. A differenza di altri grandi progetti, il codice di DeepSeek è stato rilasciato con la licenza MIT. Questo passaggio all'open source si è guadagnato il plauso della comunità, che ha iniziato a esplorare le capacità del nuovo modello.
L'aspetto più impressionante è che l'addestramento di questa nuova rete neurale è costato 20 volte meno rispetto ai concorrenti che offrono una qualità simile. L'addestramento del modello ha richiesto solo 55 giorni e 5,6 milioni di dollari. Quando DeepSeek è stato rilasciato, ha innescato uno dei più grandi cali di un giorno nella storia del mercato azionario statunitense. Anche se alla fine i mercati si sono stabilizzati, l'impatto è stato significativo.
Questo articolo esaminerà la precisione con cui i titoli dei media riflettono la realtà ed esplorerà quali configurazioni di LeaderGPU sono adatte per installare questa rete neurale.
Caratteristiche architettoniche
DeepSeek ha scelto un percorso di massima ottimizzazione, che non sorprende viste le restrizioni all'esportazione della Cina negli Stati Uniti. Queste restrizioni impediscono al Paese di utilizzare ufficialmente i modelli di GPU più avanzati per lo sviluppo dell'intelligenza artificiale.
Il modello impiega la tecnologia Multi Token Prediction (MTP), che prevede più token in una singola fase di inferenza invece di uno solo. Questo funziona grazie alla decodifica parallela dei token combinata con speciali strati mascherati che mantengono l'autoregressività.
I test MTP hanno dato risultati notevoli, aumentando la velocità di generazione di 2-4 volte rispetto ai metodi tradizionali. L'eccellente scalabilità della tecnologia la rende preziosa per le applicazioni di elaborazione del linguaggio naturale attuali e future.
Il modello Multi-Head Latent Attention (MLA) presenta un meccanismo di attenzione potenziato. Quando il modello costruisce lunghe catene di ragionamenti, mantiene l'attenzione sul contesto in ogni fase. Questa miglioria migliora la gestione dei concetti astratti e delle dipendenze dal testo.
La caratteristica principale di MLA è la capacità di regolare dinamicamente i pesi dell'attenzione su diversi livelli di astrazione. Quando elabora query complesse, MLA esamina i dati da più prospettive: il significato delle parole, la struttura delle frasi e il contesto generale. Queste prospettive formano livelli distinti che influenzano l'output finale. Per mantenere la chiarezza, MLA bilancia attentamente l'impatto di ogni livello, rimanendo concentrato sul compito principale.
Gli sviluppatori di DeepSeek hanno incorporato la tecnologia Mixture of Experts (MoE) nel modello. Essa contiene 256 reti neurali esperte pre-addestrate, ognuna specializzata per compiti diversi. Il sistema attiva 8 di queste reti per ogni input di token, consentendo un'elaborazione efficiente dei dati senza aumentare i costi di calcolo.
Nel modello completo con 671 parametri, solo 37 sono attivati per ogni token. Il modello seleziona in modo intelligente i parametri più rilevanti per l'elaborazione di ciascun token in ingresso. Questa efficiente ottimizzazione consente di risparmiare risorse computazionali mantenendo alte le prestazioni.
Una caratteristica fondamentale di qualsiasi chatbot a rete neurale è la lunghezza della finestra di contesto. Llama 2 ha un limite di contesto di 4.096 token, GPT-3.5 gestisce 16.284 token, mentre GPT-4 e DeepSeek possono elaborare fino a 128.000 token (circa 100.000 parole, equivalenti a 300 pagine di testo dattiloscritto).
R - sta per Ragionamento
DeepSeek-R1 ha acquisito un meccanismo di ragionamento simile a quello di OpenAI o1, che gli consente di gestire compiti complessi in modo più efficiente e accurato. Invece di fornire risposte immediate, il modello espande il contesto generando ragionamenti passo-passo in piccoli paragrafi. Questo approccio migliora la capacità della rete neurale di identificare relazioni complesse tra i dati, ottenendo risposte più complete e precise.
Quando si trova di fronte a un compito complesso, DeepSeek utilizza il suo meccanismo di ragionamento per scomporre il problema in componenti e analizzare ciascuno di essi separatamente. Il modello sintetizza poi questi risultati per generare una risposta per l'utente. Sebbene questo sembri essere l'approccio ideale per le reti neurali, comporta sfide significative.
Tutti i moderni LLM condividono un tratto preoccupante: le allucinazioni artificiali. Quando gli viene posta una domanda a cui non può rispondere, invece di riconoscere i propri limiti, il modello potrebbe generare risposte fittizie supportate da fatti inventati.
Se applicate a una rete neurale di ragionamento, queste allucinazioni potrebbero compromettere il processo di pensiero, basando le conclusioni su informazioni fittizie anziché reali. Ciò potrebbe portare a conclusioni errate, una sfida che i ricercatori e gli sviluppatori di reti neurali dovranno affrontare in futuro.
Consumo di VRAM
Vediamo come eseguire e testare DeepSeek R1 su un server dedicato, concentrandoci sui requisiti di memoria video della GPU.
| Modello | VRAM (Mb) | Dimensione del modello (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| deepseek-r1:8b | 6,482 | 4.9 |
| deepseek-r1:14b | 10,880 | 9 |
| deepseek-r1:32b | 21,758 | 20 |
| deepseek-r1:70b | 39,284 | 43 |
| deepseek-r1:671b | 470,091 | 404 |
Le prime tre opzioni (1.5b, 7b, 8b) sono modelli di base in grado di gestire in modo efficiente la maggior parte dei compiti. Questi modelli funzionano senza problemi su qualsiasi GPU consumer con 6-8 GB di memoria video. Le versioni di medio livello (14b e 32b) sono ideali per le attività professionali, ma richiedono più VRAM. I modelli più grandi (70b e 671b) richiedono GPU specializzate e sono utilizzati principalmente per la ricerca e le applicazioni industriali.
Selezione del server
Per aiutarvi a scegliere un server per l'inferenza DeepSeek, ecco le configurazioni ideali di LeaderGPU per ogni gruppo di modelli:
1,5b / 7b / 8b / 14b / 32b / 70b
Per questo gruppo, qualsiasi server con i seguenti tipi di GPU sarà adatto. La maggior parte dei server LeaderGPU è in grado di eseguire queste reti neurali senza problemi. Le prestazioni dipendono principalmente dal numero di core CUDA®. Si consigliano server con più GPU, come ad esempio:
671b
Ora il caso più impegnativo: come si fa a eseguire l'inferenza su un modello con una dimensione di base di 404 GB? Ciò significa che saranno necessari circa 470 GB di memoria video. LeaderGPU offre diverse configurazioni con le seguenti GPU in grado di gestire questo carico:
Entrambe le configurazioni gestiscono il carico del modello in modo efficiente, distribuendolo uniformemente su più GPU. Ad esempio, ecco come appare un server con 8xH100 dopo aver caricato il modello deepseek-r1:671b:
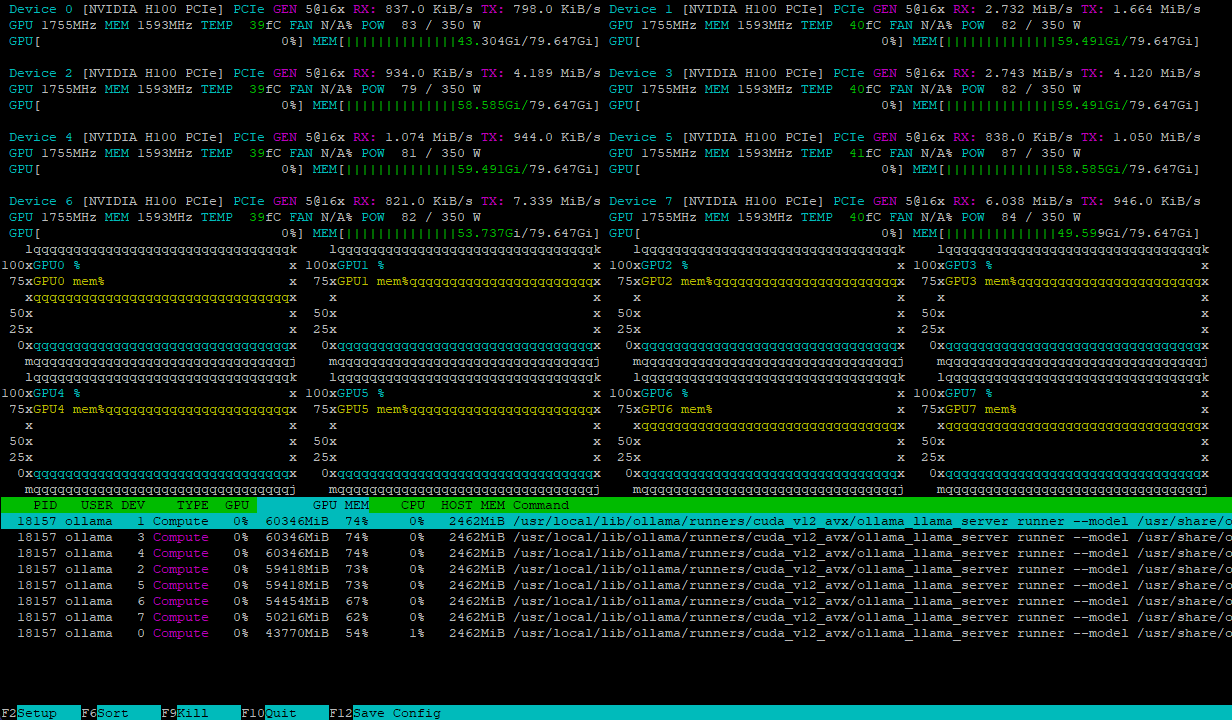
Il carico di calcolo viene bilanciato dinamicamente tra le GPU, mentre le interconnessioni NVLink® ad alta velocità impediscono i colli di bottiglia nello scambio di dati, garantendo le massime prestazioni.
Conclusione
DeepSeek-R1 combina molte tecnologie innovative come Multi Token Prediction, Multi-Head Latent Attention e Mixture of Experts in un unico modello significativo. Questo software open-source dimostra che gli LLM possono essere sviluppati in modo più efficiente con meno risorse computazionali. Il modello ha diverse versioni, dalla più piccola di 1,5b alla più grande di 671b, che richiedono hardware specializzato con più GPU di fascia alta che lavorano in parallelo.
Noleggiando un server di LeaderGPU per l'inferenza di DeepSeek-R1, avrete a disposizione un'ampia gamma di configurazioni, affidabilità e tolleranza ai guasti. Il nostro team di supporto tecnico vi aiuterà a risolvere qualsiasi problema o domanda, mentre l'installazione automatica del sistema operativo riduce i tempi di implementazione.
Scegliete il vostro server LeaderGPU e scoprite le possibilità che si aprono utilizzando i moderni modelli di reti neurali. Se avete domande, non esitate a farle nella nostra chat o via e-mail.
Aggiornato: 04.01.2026
Pubblicato: 19.02.2025




