





Qwen3-Coder: un paradigma infranto

Siamo abituati a pensare che i modelli open-source siano sempre inferiori alle loro controparti commerciali in termini di qualità. Può sembrare che siano sviluppati esclusivamente da appassionati che non possono permettersi di investire somme ingenti per creare dataset di alta qualità e addestrare i modelli su decine di migliaia di GPU moderne.
È una storia diversa quando grandi aziende come OpenAI, Anthropic o Meta si assumono il compito. Non solo dispongono delle risorse necessarie, ma anche dei migliori specialisti di reti neurali del mondo. Purtroppo, i modelli che creano, soprattutto le ultime versioni, sono closed-source. Gli sviluppatori spiegano questo fatto citando i rischi di un uso incontrollato e la necessità di garantire la sicurezza dell'IA.
Da un lato, il loro ragionamento è comprensibile: molte questioni etiche rimangono irrisolte e la natura stessa dei modelli di rete neurale permette di influenzare solo indirettamente il risultato finale. D'altra parte, mantenere i modelli chiusi e offrire l'accesso solo attraverso le proprie API è anche un modello di business solido.
Tuttavia, non tutte le aziende si comportano in questo modo. Ad esempio, l'azienda francese Mistral AI offre modelli sia commerciali che open-source, consentendo a ricercatori e appassionati di utilizzarli nei loro progetti. Ma occorre prestare particolare attenzione ai risultati ottenuti dalle aziende cinesi, la maggior parte delle quali costruisce modelli open-weight e open-source in grado di competere seriamente con le soluzioni proprietarie.
DeepSeek, Qwen3 e Kimi K2
Il primo grande passo avanti è stato fatto con DeepSeek-V3. Questo modello linguistico multimodale di DeepSeek AI è stato sviluppato con l'approccio Mixture of Experts (MoE) e conta ben 671B parametri, con 37B parametri più rilevanti attivati per ogni token. Soprattutto, tutti i suoi componenti (pesi del modello, codice di inferenza e pipeline di addestramento) sono stati resi pubblici.
Ciò lo ha reso immediatamente uno dei LLM più interessanti per gli sviluppatori di applicazioni di IA e per i ricercatori. Il successivo titolo è stato DeepSeek-R1, il primo modello di ragionamento open-source. Il giorno del suo rilascio, ha fatto tremare il mercato azionario statunitense dopo che i suoi sviluppatori hanno dichiarato che l'addestramento di un modello così avanzato era costato solo 6 milioni di dollari.
Mentre il clamore intorno a DeepSeek si è poi raffreddato, i successivi rilasci non sono stati meno importanti per l'industria globale dell'intelligenza artificiale. Stiamo parlando, ovviamente, di Qwen 3. Abbiamo parlato delle sue caratteristiche in dettaglio nel nostro articolo. Le sue caratteristiche sono state trattate in dettaglio nella nostra recensione Cosa c'è di nuovo in Qwen 3, quindi non ci soffermeremo qui. Poco dopo è apparso un altro giocatore: Kimi K2 di Moonshot AI.
Con la sua architettura MoE, i suoi parametri 1T (32B attivati per token) e il suo codice open-source, Kimi K2 ha rapidamente attirato l'attenzione della comunità. Piuttosto che concentrarsi sul ragionamento, Moonshot AI puntava a prestazioni allo stato dell'arte in matematica, programmazione e profonda conoscenza interdisciplinare.
L'asso nella manica di Kimi K2 era la sua ottimizzazione per l'integrazione negli agenti di intelligenza artificiale. Questa rete è stata letteralmente progettata per fare pieno uso di tutti gli strumenti disponibili. Eccelle in compiti che richiedono non solo la scrittura di codice, ma anche test iterativi in ogni fase di sviluppo. Tuttavia, ha anche dei punti deboli, di cui parleremo più avanti.
Kimi K2 è un modello linguistico di grandi dimensioni in tutti i sensi. L'esecuzione della versione completa richiede ~2 TB di VRAM (FP8: ~1 TB). Per ovvie ragioni, non è una cosa che si può fare a casa e nemmeno molti server con GPU sono in grado di gestirla. Il modello necessita di almeno 8 acceleratori NVIDIA® H200. Le versioni quantizzate possono essere d'aiuto, ma a un costo notevole per la precisione.
Codificatore Qwen3
Visto il successo di Moonshot AI, Alibaba ha sviluppato un proprio modello simile a Kimi K2, ma con vantaggi significativi di cui parleremo tra poco. Inizialmente è stato rilasciato in due versioni:
- Qwen3-Coder-480B-A35B-Instruct (~250 GB VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 GB di VRAM)
Pochi giorni dopo sono apparsi modelli più piccoli senza il meccanismo di ragionamento, che richiedevano una quantità di VRAM molto inferiore:
- Qwen3-Coder-30B-A3B-Instruct (~32 GB VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 GB VRAM)
Qwen3-Coder è stato progettato per l'integrazione con gli strumenti di sviluppo. Include uno speciale parser per le chiamate di funzione (qwen3coder_tool_parser.py, analogo alle chiamate di funzione di OpenAI). Insieme al modello, è stata rilasciata un'utilità per la console, in grado di svolgere funzioni che vanno dalla compilazione del codice all'interrogazione di una base di conoscenza. L'idea non è nuova, si tratta essenzialmente di un'estensione pesantemente rielaborata dell'applicazione di codice Gemini di Anthropic.
Il modello è compatibile con le API di OpenAI, consentendo di distribuirlo localmente o su un server remoto e di collegarlo alla maggior parte dei sistemi che supportano tali API. Ciò include sia applicazioni client già pronte che librerie di apprendimento automatico. Ciò lo rende utilizzabile non solo per il segmento B2C ma anche per quello B2B, offrendo una sostituzione senza soluzione di continuità del prodotto di OpenAI senza alcuna modifica della logica applicativa.
Una delle sue caratteristiche più richieste è l'estensione della lunghezza del contesto. Per impostazione predefinita, supporta 256k token, ma può essere aumentata fino a 1M utilizzando il meccanismo YaRN (Yet another RoPe extensioN). I moderni LLM sono in genere addestrati su insiemi di dati brevi (2k-8k token) e una lunghezza del contesto elevata può far perdere le tracce dei contenuti precedenti.
YaRN è un elegante "trucco" che fa credere al modello di lavorare con le solite sequenze brevi, mentre in realtà ne elabora di molto più lunghe. L'idea chiave è quella di "allungare" o "dilatare" lo spazio posizionale preservando la struttura matematica che il modello si aspetta. In questo modo è possibile elaborare efficacemente sequenze lunghe decine di migliaia di token senza dover ricorrere alla riqualificazione o alla memoria supplementare richiesta dai metodi tradizionali di estensione del contesto.
Scaricare ed eseguire l'inferenza
Assicurarsi di aver installato CUDA® in precedenza, utilizzando le istruzioni ufficiali di NVIDIA® o la guida Installare il toolkit CUDA® in Linux. Per verificare la presenza del compilatore richiesto:
nvcc --versionRisultato atteso:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
Se si ottiene:
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
è necessario aggiungere i binari di CUDA® a $PATH del sistema.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHQuesta è una soluzione temporanea. Per una soluzione definitiva, modificare ~/.bashrc e aggiungere le stesse due righe alla fine.
Ora, preparate il vostro sistema per gestire gli ambienti virtuali. Si può usare il venv integrato in Python o il più avanzato Miniforge. Supponendo che Miniforge sia installato:
conda create -n venv python=3.10conda activate venvInstallare PyTorch con il supporto CUDA® corrispondente al sistema:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124Installare quindi le librerie essenziali:
- Transformers - La libreria di modelli principale di Hugging Face
- Accelerate - consente l'inferenza multi-GPU
- HuggingFace Hub - per il download/upload di modelli e set di dati
- Safetensors - formato sicuro per i pesi dei modelli
- vLLM - libreria di inferenza raccomandata per Qwen
pip install transformers accelerate huggingface_hub safetensors vllmScaricare il modello:
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BEseguire l'inferenza con il parallelismo dei tensori (dividendo i tensori degli strati tra le GPU, ad esempio 8):
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000Avvia il server API OpenAI di vLLM.
Test e integrazione
cURL
Installare jq per la stampa di JSON:
sudo apt -y install jqTestare il server:
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
Per integrarsi con Visual Studio Code, installare l'estensione Continue e aggiungerla a config.yaml:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply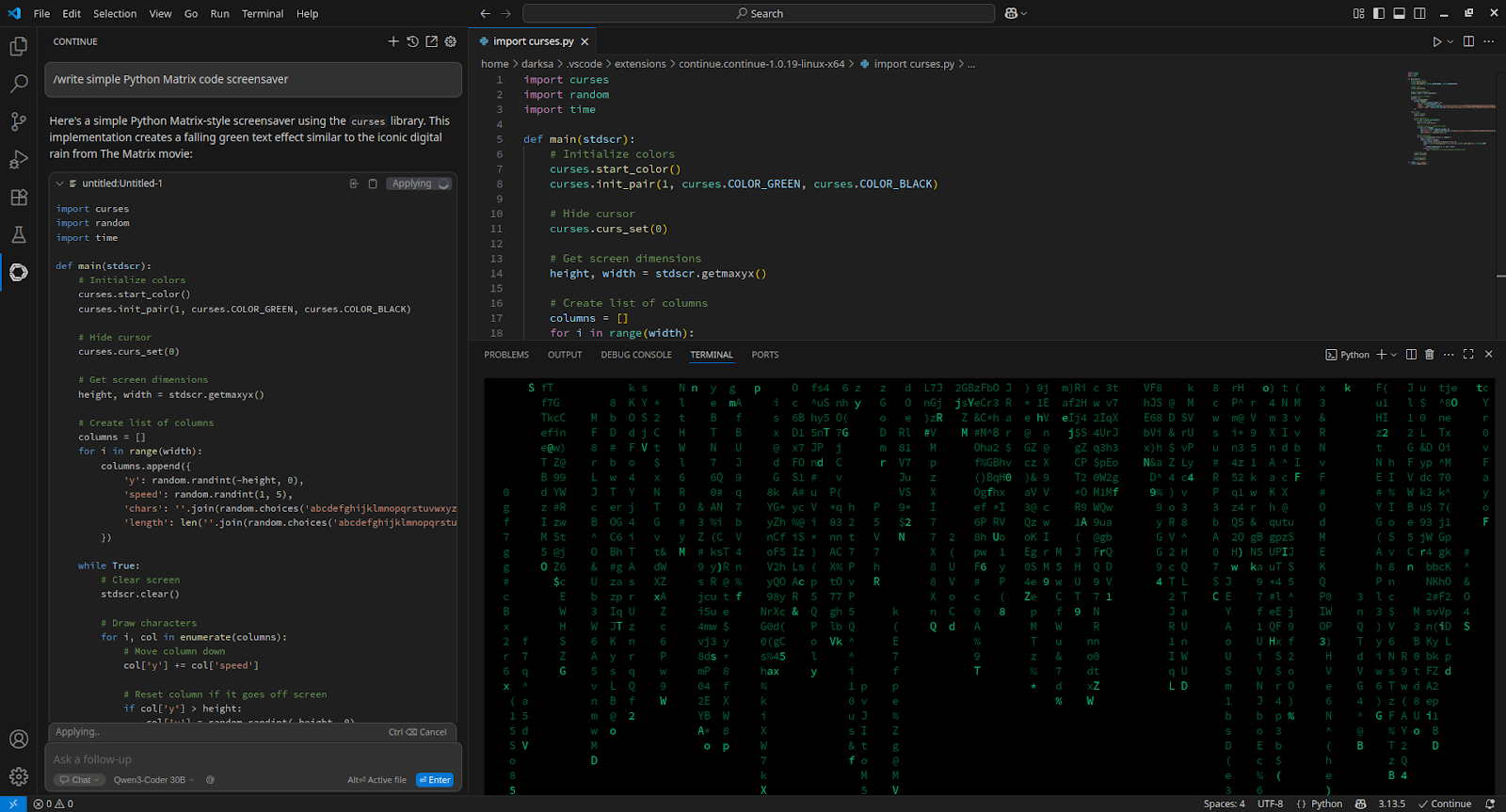
Qwen-Agent
Per una configurazione basata su GUI con Qwen-Agent (compresi RAG, MCP e interprete di codice):
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Aprire l'editor nano:
nano script.pyEsempio di script Python per lanciare Qwen-Agent con una WebUI Gradio:
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Eseguire lo script:
python script.pyIl server sarà disponibile all'indirizzo: http://127.0.0.1:7860
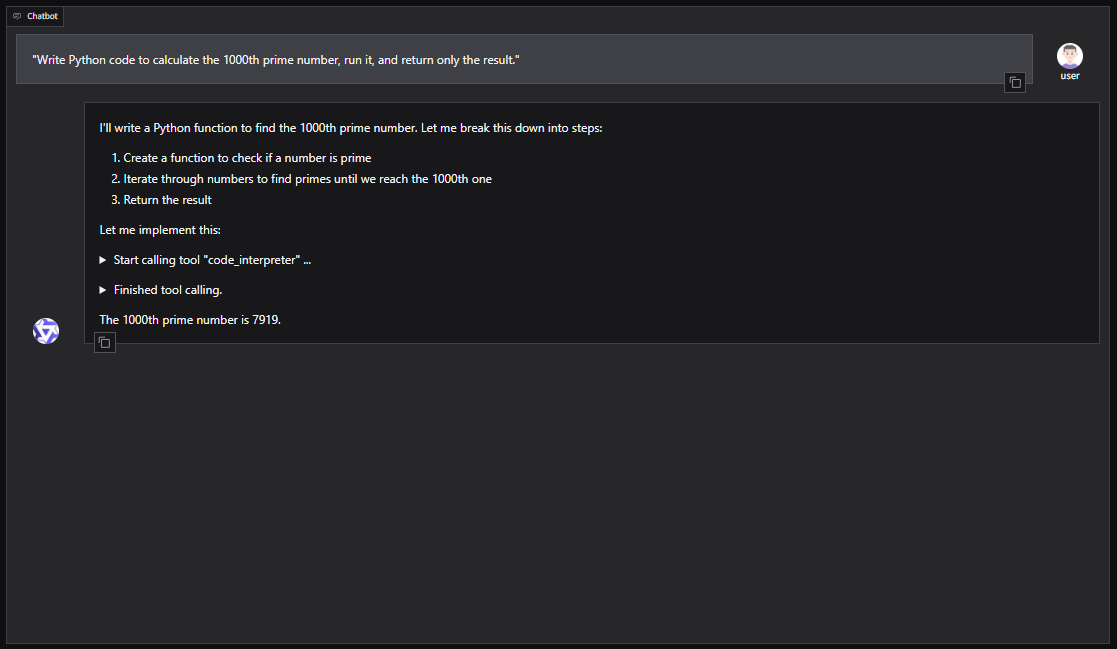
È anche possibile integrare Qwen3-Coder in framework di agenti come CrewAI per automatizzare compiti complessi con set di strumenti come la ricerca sul web o la memoria di database vettoriali.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 12.08.2025




