





Che cos'è la distillazione della conoscenza
I Large Language Models (LLM) sono diventati parte integrante della nostra vita grazie alle loro capacità uniche. Comprendono il contesto e generano testi coerenti ed estesi sulla base di esso. Possono elaborare e rispondere in qualsiasi lingua, tenendo conto delle sfumature culturali di ciascuna.
I LLM eccellono nella risoluzione di problemi complessi, nella programmazione, nella gestione di conversazioni e altro ancora. Questa versatilità deriva dall'elaborazione di grandi quantità di dati di addestramento, da cui il termine "grandi". Questi modelli possono contenere decine o centinaia di miliardi di parametri, il che li rende molto impegnativi per l'uso quotidiano.
L'addestramento è il processo più impegnativo. I modelli di rete neurale imparano elaborando enormi serie di dati, regolando i loro "pesi" interni per formare connessioni stabili tra i neuroni. Queste connessioni memorizzano le conoscenze che la rete neurale addestrata può utilizzare in seguito sui dispositivi finali.
Tuttavia, la maggior parte dei dispositivi finali non dispone della potenza di calcolo necessaria per eseguire questi modelli. Per esempio, l'esecuzione della versione completa di Llama 2 (70B parametri) richiede una GPU con 48 GB di memoria video, hardware che pochi utenti hanno a casa, figuriamoci sui dispositivi mobili.
Di conseguenza, la maggior parte delle reti neurali moderne opera in infrastrutture cloud piuttosto che su dispositivi portatili, che vi accedono tramite API. Tuttavia, i produttori di dispositivi stanno facendo progressi in due modi: dotando i dispositivi di unità di calcolo specializzate come le NPU e sviluppando metodi per migliorare le prestazioni dei modelli di rete neurale compatti.
Ridurre le dimensioni
Tagliare l'eccesso
La quantizzazione è il primo e più efficace metodo per ridurre le dimensioni della rete neurale. I pesi delle reti neurali utilizzano in genere numeri in virgola mobile a 32 bit, ma è possibile ridurli cambiando il formato. L'uso di valori a 8 bit (o addirittura binari in alcuni casi) può ridurre le dimensioni della rete di dieci volte, anche se questo riduce significativamente l'accuratezza delle risposte.
Un altro approccio è la potatura, che rimuove le connessioni non importanti nella rete neurale. Questo processo funziona sia durante l'addestramento sia con le reti completate. Oltre alle semplici connessioni, il pruning può rimuovere neuroni o interi strati. Questa riduzione dei parametri e delle connessioni porta a una riduzione dei requisiti di memoria.
La decomposizione di matrici o tensori è la terza tecnica comune di riduzione delle dimensioni. La scomposizione di una matrice di grandi dimensioni in un prodotto di tre matrici più piccole riduce i parametri totali mantenendo la qualità. Questo può ridurre le dimensioni della rete di decine di volte. La decomposizione tensoriale offre risultati ancora migliori, ma richiede più iperparametri.
Sebbene questi metodi riducano efficacemente le dimensioni, tutti devono affrontare il problema della perdita di qualità. I modelli compressi di grandi dimensioni superano le loro controparti più piccole e non compresse, ma ogni compressione rischia di ridurre l'accuratezza delle risposte. La distillazione della conoscenza rappresenta un interessante tentativo di bilanciare qualità e dimensioni.
Proviamo insieme
La distillazione della conoscenza si spiega meglio con l'analogia tra studente e insegnante. Mentre gli studenti imparano, gli insegnanti insegnano e aggiornano continuamente le loro conoscenze. Quando entrambi si imbattono in nuove conoscenze, l'insegnante è avvantaggiato: può attingere alle sue ampie conoscenze in altri settori, mentre lo studente non ha ancora queste basi.
Questo principio si applica alle reti neurali. Quando si addestrano due reti neurali dello stesso tipo ma di dimensioni diverse su dati identici, la rete più grande di solito ottiene risultati migliori. La sua maggiore capacità di "conoscenza" consente di ottenere risposte più precise rispetto alla sua controparte più piccola. Ciò solleva una possibilità interessante: perché non addestrare la rete più piccola non solo sul set di dati, ma anche sulle uscite più accurate della rete più grande?
Questo processo è la distillazione della conoscenza: una forma di apprendimento supervisionato in cui un modello più piccolo impara a replicare le previsioni di uno più grande. Se da un lato questa tecnica aiuta a compensare la perdita di qualità dovuta alla riduzione delle dimensioni della rete neurale, dall'altro richiede risorse computazionali e tempo di addestramento aggiuntivi.
Software e logica
Chiarite le basi teoriche, esaminiamo il processo da un punto di vista tecnico. Inizieremo con gli strumenti software che possono guidare l'utente attraverso le fasi di formazione e di distillazione della conoscenza.
Python, insieme alla libreria TorchTune dell'ecosistema PyTorch, offre l'approccio più semplice per lo studio e la messa a punto di modelli linguistici di grandi dimensioni. Ecco come funziona l'applicazione:
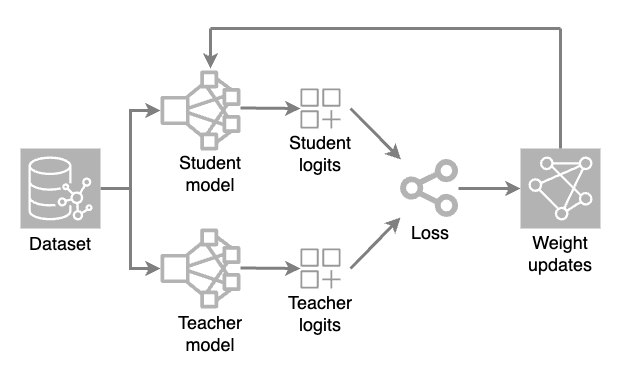
Vengono caricati due modelli: un modello completo (insegnante) e un modello ridotto (studente). Durante ogni iterazione di addestramento, il modello insegnante genera previsioni ad alta temperatura, mentre il modello studente elabora il set di dati per fare le proprie previsioni.
I valori di output grezzi (logit) di entrambi i modelli vengono valutati attraverso una funzione di perdita (una misura numerica di quanto una previsione si discosta dal valore corretto). Gli aggiustamenti del peso vengono quindi applicati al modello studente attraverso la retropropagazione. Ciò consente al modello più piccolo di apprendere e replicare le previsioni del modello insegnante.
Il file di configurazione principale nel codice dell'applicazione è chiamato ricetta. Questo file memorizza tutti i parametri e le impostazioni della distillazione, rendendo gli esperimenti riproducibili e consentendo ai ricercatori di monitorare l'influenza dei diversi parametri sul risultato finale.
Quando si selezionano i valori dei parametri e il numero di iterazioni, è fondamentale mantenere l'equilibrio. Un modello troppo distillato può perdere la sua capacità di riconoscere i dettagli più sottili e il contesto, passando a risposte predefinite. Anche se un equilibrio perfetto è quasi impossibile da raggiungere, un attento monitoraggio del processo di distillazione può migliorare sostanzialmente la qualità di previsione anche di modelli di reti neurali modesti.
Vale la pena di prestare attenzione anche al monitoraggio durante il processo di addestramento. Questo aiuterà a identificare in tempo i problemi e a correggerli tempestivamente. A tale scopo, è possibile utilizzare lo strumento TensorBoard. Si integra perfettamente nei progetti PyTorch e consente di valutare visivamente molte metriche, come l'accuratezza e le perdite. Inoltre, consente di costruire un grafico del modello, di tenere traccia dell'utilizzo della memoria e del tempo di esecuzione delle operazioni.
Conclusione
La distillazione della conoscenza è un metodo efficace per ottimizzare le reti neurali e migliorare i modelli compatti. Funziona meglio quando è essenziale bilanciare le prestazioni con la qualità delle risposte.
Sebbene la distillazione della conoscenza richieda un attento monitoraggio, i suoi risultati possono essere notevoli. I modelli diventano molto più piccoli, pur mantenendo la qualità della previsione, e funzionano meglio con meno risorse di calcolo.
Se ben pianificata con parametri adeguati, la distillazione della conoscenza è uno strumento fondamentale per creare reti neurali compatte senza sacrificare la qualità.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 23.01.2025




