





Triton™ Inference Server

I requisiti aziendali possono variare, ma tutti condividono un principio fondamentale: i sistemi devono funzionare rapidamente e fornire la massima qualità possibile. Quando si tratta di inferenza di reti neurali, l'uso efficiente delle risorse di calcolo diventa fondamentale. Qualsiasi sottoutilizzo della GPU o tempo di inattività si traduce direttamente in perdite finanziarie.
Consideriamo un mercato come esempio. Queste piattaforme ospitano numerosi prodotti, ciascuno con diversi attributi: descrizioni testuali, specifiche tecniche, categorie e contenuti multimediali come foto e video. Tutti i contenuti richiedono una moderazione per mantenere condizioni eque per i venditori ed evitare che merci vietate o contenuti illegali appaiano sulla piattaforma.
La moderazione manuale è possibile, ma è lenta e inefficiente. Nell'ambiente competitivo di oggi, i venditori hanno bisogno di espandere rapidamente la propria gamma di prodotti: più velocemente gli articoli appaiono sul marketplace, maggiori sono le possibilità di essere scoperti e acquistati. La moderazione manuale è inoltre costosa e soggetta a errori umani, che potrebbero consentire il passaggio di contenuti inappropriati.
La moderazione automatica, che utilizza reti neurali appositamente addestrate, offre una soluzione. Questo approccio offre molteplici vantaggi: riduce sostanzialmente i costi di moderazione, migliorando al contempo la qualità. Le reti neurali elaborano i contenuti molto più velocemente degli esseri umani, consentendo ai venditori di superare più rapidamente la fase di moderazione, soprattutto quando si gestiscono grandi volumi di prodotti.
L'approccio ha le sue sfide. L'implementazione di una moderazione automatizzata richiede lo sviluppo e l'addestramento di modelli di reti neurali, che richiedono personale qualificato e notevoli risorse informatiche. Tuttavia, i vantaggi diventano evidenti subito dopo l'implementazione iniziale. L'aggiunta dell'implementazione automatica dei modelli può snellire in modo significativo le operazioni in corso.
Inferenza
Supponiamo di aver capito le procedure di apprendimento automatico. Il passo successivo è determinare come eseguire l'inferenza del modello su un server in affitto. Per un singolo modello, di solito si sceglie uno strumento che funziona bene con il framework specifico su cui è stato costruito. Tuttavia, quando si ha a che fare con più modelli creati in framework diversi, si hanno due opzioni.
Si possono convertire tutti i modelli in un unico formato, oppure scegliere uno strumento che supporti più framework. Triton™ Inference Server si adatta perfettamente al secondo approccio. Supporta i seguenti backend:
- TensorRT™
- TensorRT-LLM
- vLLM
- Pitone
- PyTorch (LibTorch)
- Runtime ONNX
- Tensorflow
- FIL
- DALI
Inoltre, è possibile utilizzare qualsiasi applicazione come backend. Ad esempio, se avete bisogno di una post-elaborazione con un'applicazione C/C++, potete integrarla senza problemi.
Scalare
Triton™ Inference Server gestisce in modo efficiente le risorse di calcolo su un singolo server eseguendo più modelli contemporaneamente e distribuendo il carico di lavoro sulle GPU.
L'installazione avviene tramite un container Docker. Gli ingegneri DevOps possono controllare l'allocazione delle GPU all'avvio, scegliendo di utilizzare tutte le GPU o di limitarne il numero. Sebbene il software non gestisca direttamente lo scaling orizzontale, è possibile utilizzare bilanciatori di carico tradizionali come HAproxy o distribuire le applicazioni in un cluster Kubernetes.
Preparazione del sistema
Per configurare Triton™ su un server LeaderGPU con Ubuntu 22.04, aggiornare prima il sistema con questo comando:
sudo apt update && sudo apt -y upgradeInnanzitutto, installare i driver NVIDIA® utilizzando lo script di autoinstallazione:
sudo ubuntu-drivers autoinstallRiavviare il server per applicare le modifiche:
sudo shutdown -r nowUna Volta™ che il server è di nuovo online, installare Docker utilizzando il seguente script di installazione:
curl -sSL https://get.docker.com/ | shPoiché Docker non è in grado di passare le GPU ai container per impostazione predefinita, è necessario NVIDIA® Container Toolkit. Aggiungere il repository NVIDIA® scaricando e registrando la sua chiave GPG:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listAggiornare la cache dei pacchetti e installare il toolkit:
sudo apt update && sudo apt -y install nvidia-container-toolkitRiavviare Docker per abilitare le nuove funzionalità:
sudo systemctl restart dockerIl sistema operativo è ora pronto all'uso.
Installazione del server di inferenza Triton™
Scarichiamo il repository del progetto:
git clone https://github.com/triton-inference-server/serverQuesto repository contiene esempi di reti neurali preconfigurate e uno script per il download del modello. Navigare nella directory examples:
cd server/docs/examplesScaricare i modelli eseguendo il seguente script, che li salverà in ~/server/docs/examples/model_repository:
./fetch_models.shL'architettura di Triton™ Inference Server richiede che i modelli siano memorizzati separatamente. È possibile memorizzarli localmente in una qualsiasi directory del server o su una memoria di rete. Quando si avvia il server, è necessario montare questa directory nel contenitore nel punto di montaggio /models. Questo serve come repository per tutte le versioni dei modelli.
Avviare il contenitore con questo comando
sudo docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ~/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:25.01-py3 tritonserver --model-repository=/modelsEcco cosa fa ogni parametro:
- --gpus=all specifica che tutte le GPU disponibili saranno utilizzate nel server;
- --rm distrugge il contenitore dopo il completamento o l'arresto del processo;
- -p8000:8000 inoltra la porta 8000 per ricevere le richieste HTTP;
- -p8001:8001 inoltra la porta 8001 per ricevere le richieste gRPC;
- -p8002:8002 inoltra la porta 8002 per richiedere le metriche;
- -v ~/server/docs/examples/model_repository:/models inoltra la directory con i modelli;
- nvcr.io/nvidia/tritonserver:25.01-py3 indirizzo del contenitore dal catalogo NGC;
- tritonserver --model-repository=/models lancia il Triton™ Inference Server con la posizione del repository dei modelli a /models.
L'output del comando mostrerà tutti i modelli disponibili nel repository, ognuno pronto ad accettare richieste:
+----------------------+---------+--------+ | Model | Version | Status | +----------------------+---------+--------+ | densenet_onnx | 1 | READY | | inception_graphdef | 1 | READY | | simple | 1 | READY | | simple_dyna_sequence | 1 | READY | | simple_identity | 1 | READY | | simple_int8 | 1 | READY | | simple_sequence | 1 | READY | | simple_string | 1 | READY | +----------------------+---------+--------+
I tre servizi sono stati lanciati con successo sulle porte 8000, 8001 e 8002:
I0217 08:00:34.930188 1 grpc_server.cc:2466] Started GRPCInferenceService at 0.0.0.0:8001 I0217 08:00:34.930393 1 http_server.cc:4636] Started HTTPService at 0.0.0.0:8000 I0217 08:00:34.972340 1 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002
Utilizzando l'utilità nvtop, possiamo verificare che tutte le GPU sono pronte ad accettare il carico:
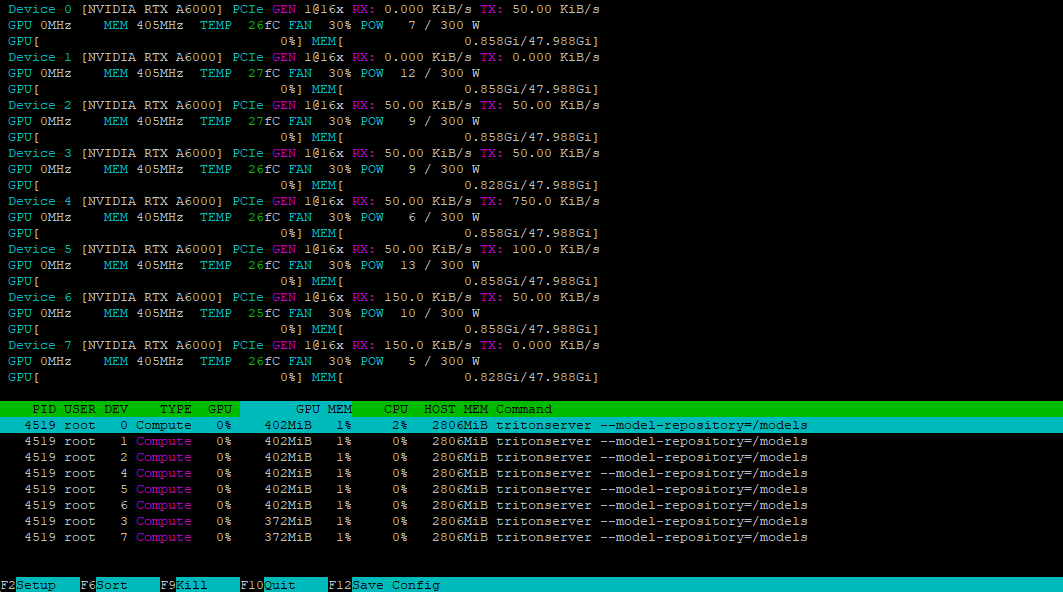
Installazione del client
Per accedere al nostro server, dobbiamo generare una richiesta appropriata usando il client incluso nell'SDK. Possiamo scaricare questo SDK come contenitore Docker:
sudo docker pull nvcr.io/nvidia/tritonserver:25.01-py3-sdkEseguire il contenitore in modalità interattiva per accedere alla console:
sudo docker run -it --gpus=all --rm --net=host nvcr.io/nvidia/tritonserver:25.01-py3-sdkVerifichiamo questo con il modello DenseNet in formato ONNX, utilizzando il metodo INCEPTION per preelaborare e analizzare l'immagine mug.jpg:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpgIl client contatterà il server, che creerà un batch e lo elaborerà utilizzando le GPU disponibili nel container. Ecco l'output:
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349562 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424891 (505) = COFFEEPOTPreparazione del repository
Affinché Triton™ gestisca correttamente i modelli, è necessario preparare il repository in un modo specifico. Ecco la struttura della directory:
model_repository/
└── your_model/
├── config.pbtxt
└── 1/
└── model.*
Ogni modello ha bisogno di una propria directory contenente un file di configurazione config.pbtxt con la sua descrizione. Ecco un esempio:
name: "Test"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "INPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]In questo esempio, un modello chiamato Test verrà eseguito sul backend PyTorch. Il parametro max_batch_size imposta il numero massimo di elementi che possono essere elaborati simultaneamente, consentendo un efficiente bilanciamento del carico tra le risorse. L'impostazione di questo valore a zero disabilita il batching, facendo sì che il modello elabori le richieste in modo sequenziale.
Il modello accetta un ingresso e produce un'uscita, entrambi utilizzando il tipo di numero FP32. I parametri devono corrispondere esattamente ai requisiti del modello. Per l'elaborazione delle immagini, una tipica specifica di dimensione è dims: [ 3, 224, 224 ], dove:
- 3 - numero di canali di colore (RGB);
- 224 - altezza dell'immagine in pixel;
- 224 - larghezza dell'immagine in pixel.
L'output dims: [ 1000 ] rappresenta un vettore unidimensionale di 1000 elementi, adatto alle attività di classificazione delle immagini. Per determinare la dimensione corretta del modello, consultare la relativa documentazione. Se il file di configurazione è incompleto, Triton™ cercherà di generare automaticamente i parametri mancanti.
Avvio di un modello personalizzato
Avviamo l'inferenza del modello DeepSeek-R1 distillato di cui abbiamo parlato in precedenza. Per prima cosa, creeremo la struttura di directory necessaria:
mkdir ~/model_repository && mkdir ~/model_repository/deepseek && mkdir ~/model_repository/deepseek/1Navigare nella directory del modello:
cd ~/model_repository/deepseekCreare un file di configurazione config.pbtxt:
nano config.pbtxtIncollare quanto segue:
# Copyright 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of NVIDIA CORPORATION nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Note: You do not need to change any fields in this configuration.
backend: "vllm"
# The usage of device is deferred to the vLLM engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]Salvare il file premendo Ctrl + O, poi l'editor con Ctrl + X. Navigare nella directory 1:
cd 1Creare un file di configurazione del modello model.json con i seguenti parametri:
{
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"disable_log_requests": true,
"gpu_memory_utilization": 0.9,
"enforce_eager": true
}Si noti che il valore di gpu_memory_utilization varia a seconda della GPU e deve essere determinato sperimentalmente. Per questa guida, useremo 0.9. La struttura della directory all'interno di ~/model_repository dovrebbe ora apparire come segue:
└── deepseek
├── 1
│ └── model.json
└── config.pbtxt
Impostare la variabile LOCAL_MODEL_REPOSITORY per comodità:
LOCAL_MODEL_REPOSITORY=~/model_repository/Avviare il server di inferenza con questo comando:
sudo docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 tritonserver --model-repository=model_repository/Ecco cosa fa ogni parametro:
- --rm rimuove automaticamente il contenitore dopo l'arresto;
- -it esegue il contenitore in modalità interattiva con output da terminale;
- --net utilizza lo stack di rete dell'host invece dell'isolamento del contenitore;
- --shm-size=2g imposta la memoria condivisa a 2 GB;
- --ulimit memlock=-1 rimuove il limite di blocco della memoria;
- --ulimit stack=67108864 imposta la dimensione dello stack a 64 MB;
- --gpus all abilita l'accesso a tutte le GPU del server;
- -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository monta la directory locale del modello nel contenitore;
- nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 specifica il contenitore con il supporto del backend vLLM;
- tritonserver --model-repository=model_repository/ lancia il Triton™ Inference Server con la posizione del repository dei modelli in model_repository.
Testare il server inviando una richiesta con curl, utilizzando un semplice prompt e un limite di risposta di 4096 token:
curl -X POST localhost:8000/v2/models/deepseek/generate -d '{"text_input": "Tell me about the Netherlands?", "max_tokens": 4096}'Il server riceve ed elabora con successo la richiesta.
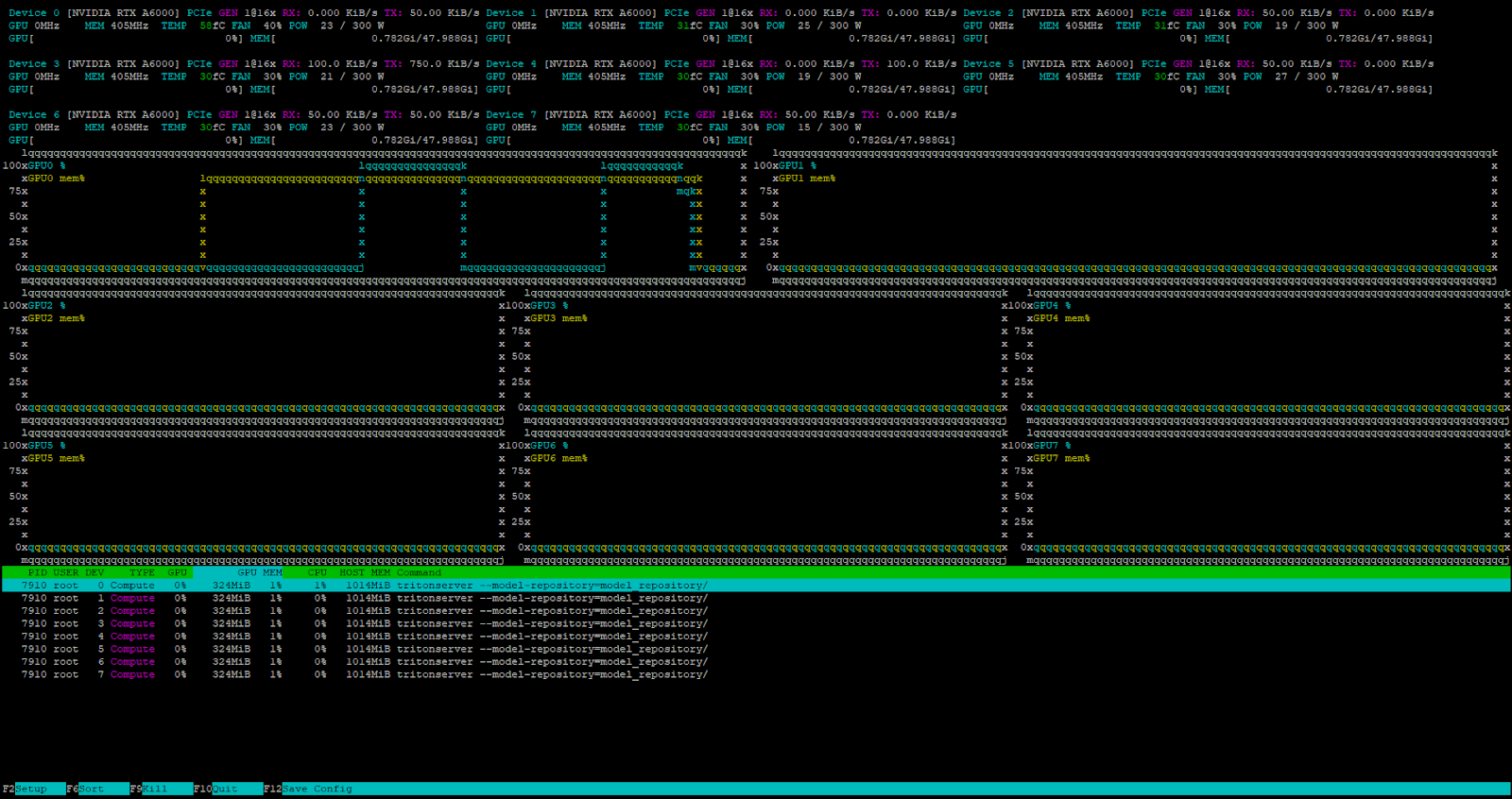
Il task scheduler interno di Triton™ gestisce tutte le richieste in arrivo quando il server è sotto carico.
Conclusione
Triton™ Inference Server eccelle nell'implementazione di modelli di apprendimento automatico in produzione, distribuendo in modo efficiente le richieste sulle GPU disponibili. Questo massimizza l'uso delle risorse del server in affitto e riduce i costi dell'infrastruttura di calcolo. Il software funziona con diversi backend, tra cui vLLM per modelli linguistici di grandi dimensioni.
Poiché si installa come contenitore Docker, è possibile integrarlo facilmente in qualsiasi pipeline CI/CD moderna. Provatelo voi stessi noleggiando un server da LeaderGPU.
Aggiornato: 04.01.2026
Pubblicato: 26.02.2025




