





Il proprio Qwen utilizzando HF

I grandi modelli di reti neurali, con le loro straordinarie capacità, sono saldamente radicati nelle nostre vite. Riconoscendo questa opportunità di sviluppo futuro, le grandi aziende hanno iniziato a sviluppare le proprie versioni di questi modelli. Il gigante cinese Alibaba non è rimasto a guardare. Ha creato il proprio modello, QWen (Tongyi Qianwen), che è diventato la base per molti altri modelli di reti neurali.
Prerequisiti
Aggiornare la cache e i pacchetti
Aggiorniamo la cache dei pacchetti e aggiorniamo il sistema operativo prima di iniziare a configurare Qwen. Inoltre, dobbiamo aggiungere Python Installer Packages (PIP), se non è già presente nel sistema. Si noti che per questa guida utilizziamo Ubuntu 22.04 LTS come sistema operativo:
sudo apt update && sudo apt -y upgrade && sudo apt install python3-pipInstallare i driver NVIDIA®
È possibile utilizzare l'utilità automatica inclusa di default nelle distribuzioni Ubuntu:
sudo ubuntu-drivers autoinstallIn alternativa, è possibile installare manualmente i driver NVIDIA® utilizzando la nostra guida passo-passo. Non dimenticate di riavviare il server:
sudo shutdown -r nowGenerazione di testo dell'interfaccia web
Clonare il repository
Aprire la cartella di lavoro sull'SSD:
cd /mnt/fastdiskClonare il repository del progetto:
git clone https://github.com/oobabooga/text-generation-webui.gitInstallare i requisiti
Aprire la cartella scaricata:
cd text-generation-webuiControllare e installare tutti i componenti mancanti:
pip install -r requirements.txtAggiungere la chiave SSH a HF
Prima di iniziare, è necessario impostare il port forwarding (porta remota 7860 a 127.0.0.1:7860) nel proprio client SSH. Per ulteriori informazioni, consultare il seguente articolo: Connettersi al server Linux.
Aggiornare il repository della cache dei pacchetti e i pacchetti installati:
sudo apt update && sudo apt -y upgradeGenerare e aggiungere una chiave SSH da utilizzare in Hugging Face:
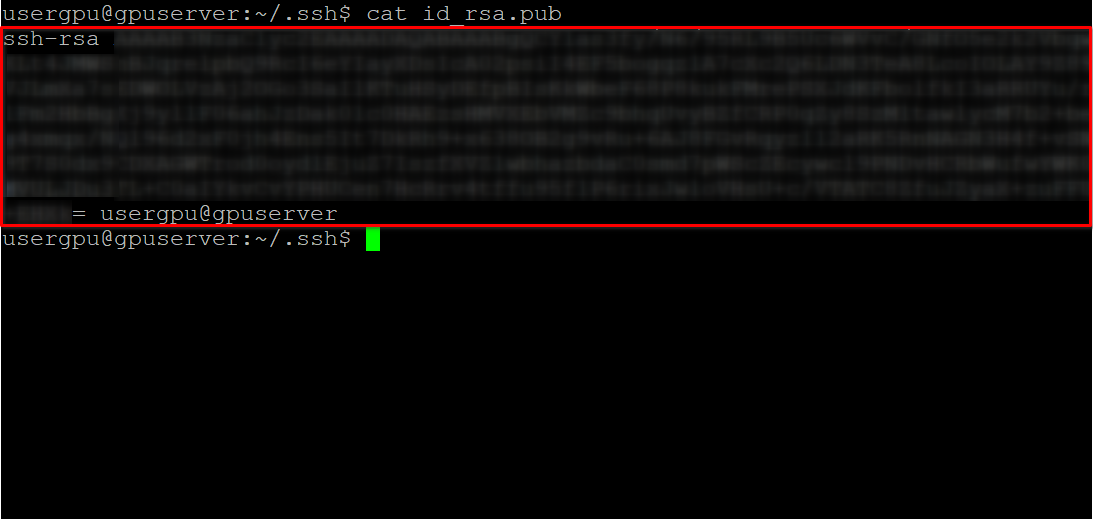
cd ~/.ssh && ssh-keygenQuando la coppia di chiavi è stata generata, è possibile visualizzare la chiave pubblica nell'emulatore di terminale:
cat id_rsa.pubCopiare tutte le informazioni che iniziano con ssh-rsa e terminano con usergpu@gpuserver come mostrato nella seguente schermata:
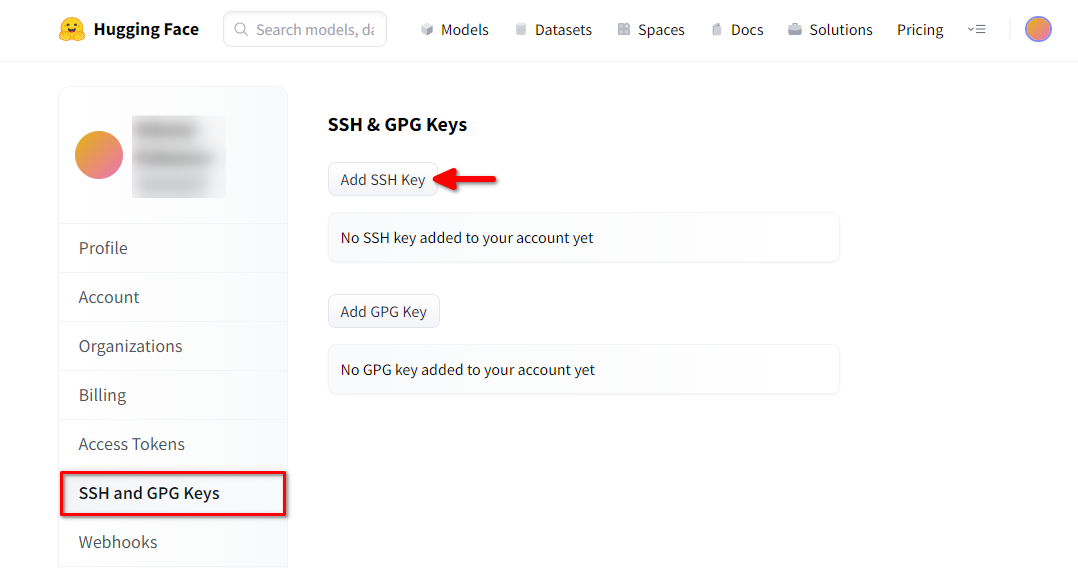
Aprire un browser web, digitare https://huggingface.co/ nella barra degli indirizzi e premere Enter. Accedere al proprio account HF e aprire Impostazioni profilo. Scegliere quindi SSH and GPG Keys e fare clic sul pulsante Add SSH Key:
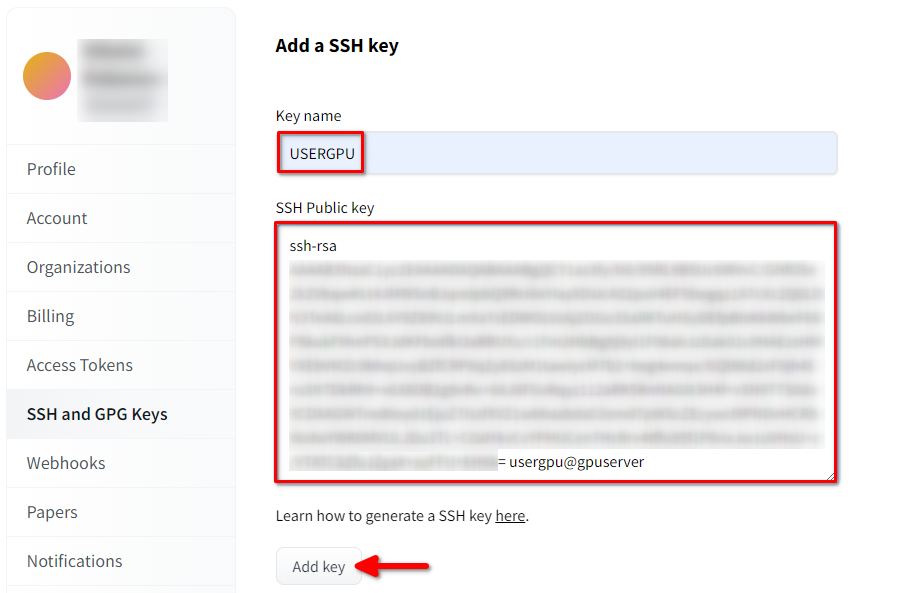
Compilare Key name e incollare la SSH Public key copiata dal terminale. Salvare la chiave premendo Add key:
Ora il vostro account HF è collegato alla chiave SSH pubblica. La seconda parte (chiave privata) è memorizzata sul server. Il passo successivo consiste nell'installare un'estensione specifica di Git LFS (Large File Storage), utilizzata per scaricare file di grandi dimensioni come i modelli di reti neurali. Aprire la propria home directory:
cd ~/Scaricare ed eseguire lo script di shell. Questo script installa un nuovo repository di terze parti con git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashOra è possibile installarlo utilizzando il gestore di pacchetti standard:
sudo apt-get install git-lfsConfiguriamo git per usare il nostro nickname HF:
git config --global user.name "John"E collegato all'account di posta elettronica HF:
git config --global user.email "john.doe@example.com"Scarica il modello
Il passo successivo è scaricare il modello utilizzando la tecnica di clonazione del repository comunemente usata dagli sviluppatori di software. L'unica differenza è che Git-LFS, precedentemente installato, elaborerà automaticamente i file puntatori contrassegnati e scaricherà tutto il contenuto. Aprire la directory necessaria (/mnt/fastdisk nel nostro esempio):
cd /mnt/fastdiskQuesto comando potrebbe richiedere un po' di tempo per essere completato:
git clone git@hf.co:Qwen/Qwen1.5-32B-Chat-GGUFEseguire il modello
Eseguire uno script che avvii il server web e specifichi /mnt/fastdisk come directory di lavoro con i modelli. Questo script potrebbe scaricare alcuni componenti aggiuntivi al primo avvio.
./start_linux.sh --model-dir /mnt/fastdiskAprire il browser Web e selezionare llama.cpp dall'elenco a discesa Model loader:
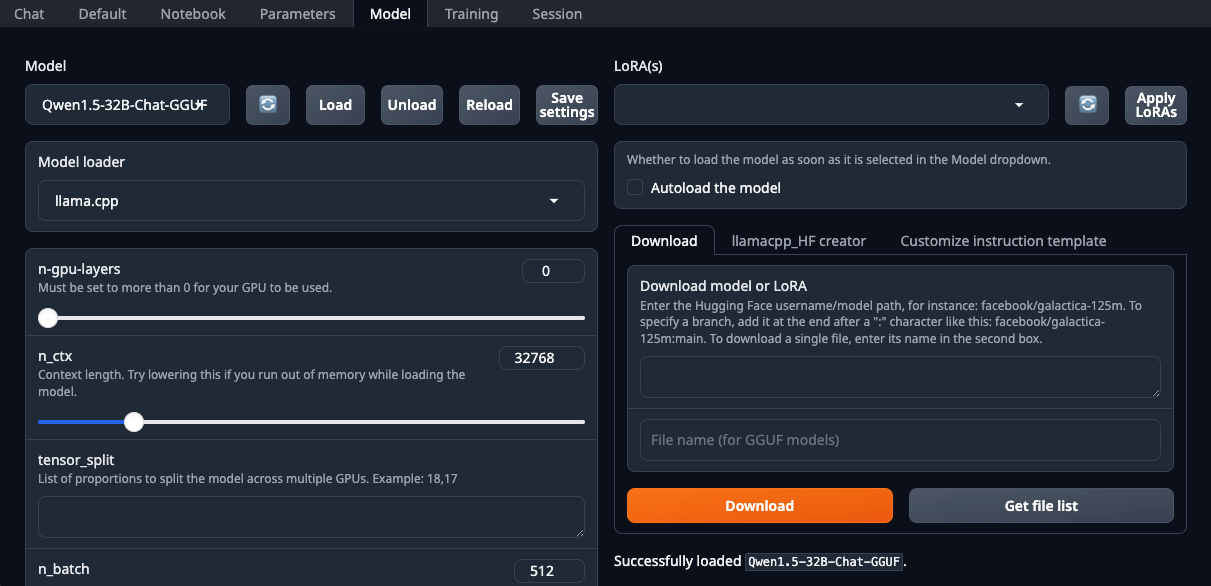
Assicurarsi di impostare il parametro n-gpu-layers. È lui il responsabile della percentuale di calcoli che verrà scaricata sulla GPU. Se si lascia il numero a 0, tutti i calcoli verranno eseguiti dalla CPU, il che è piuttosto lento. Una Volta™ impostati tutti i parametri, fare clic sul pulsante Load. Successivamente, passare alla scheda Chat e selezionare Instruct mode. A questo punto, è possibile inserire qualsiasi richiesta e ricevere una risposta:
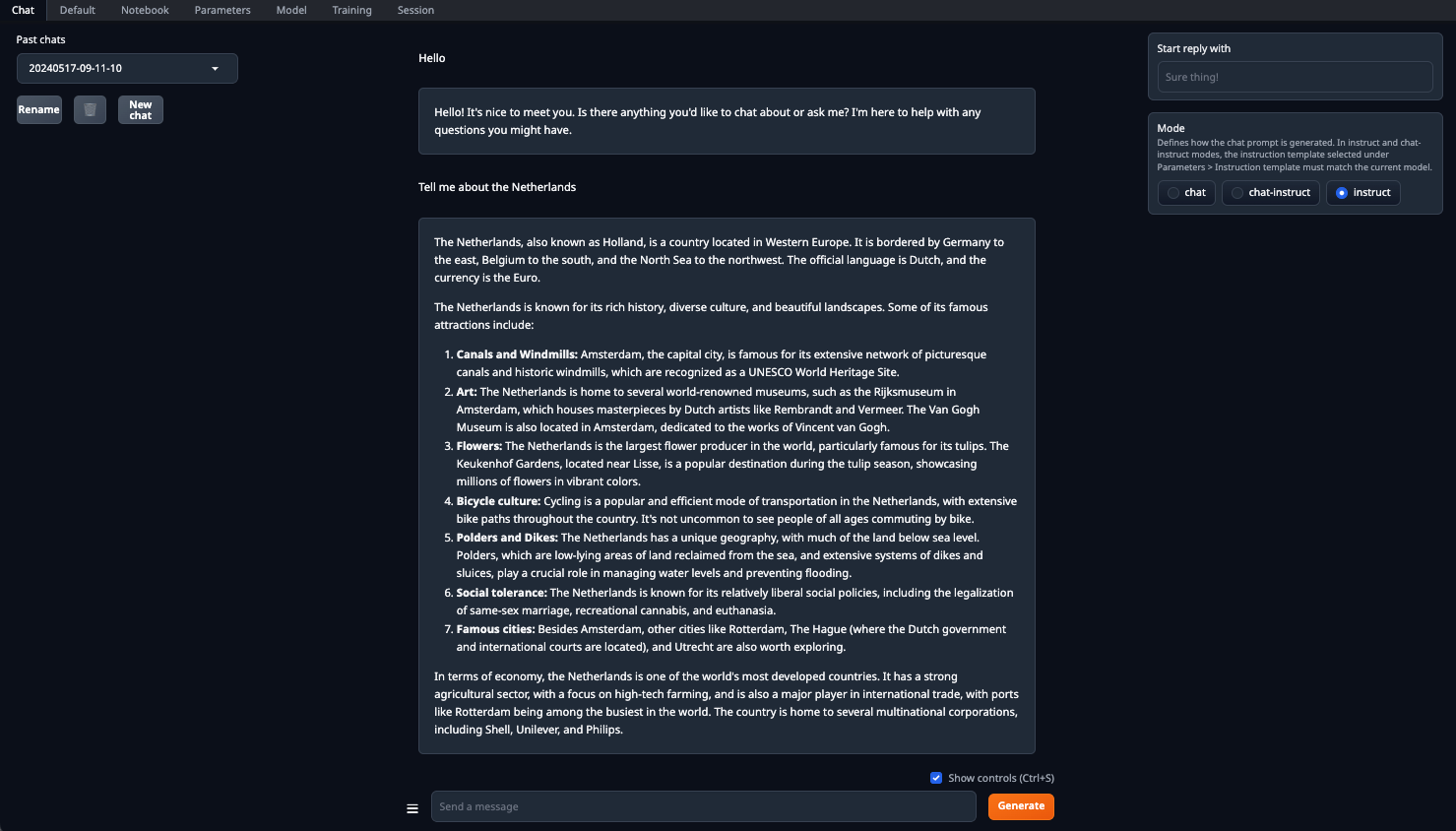
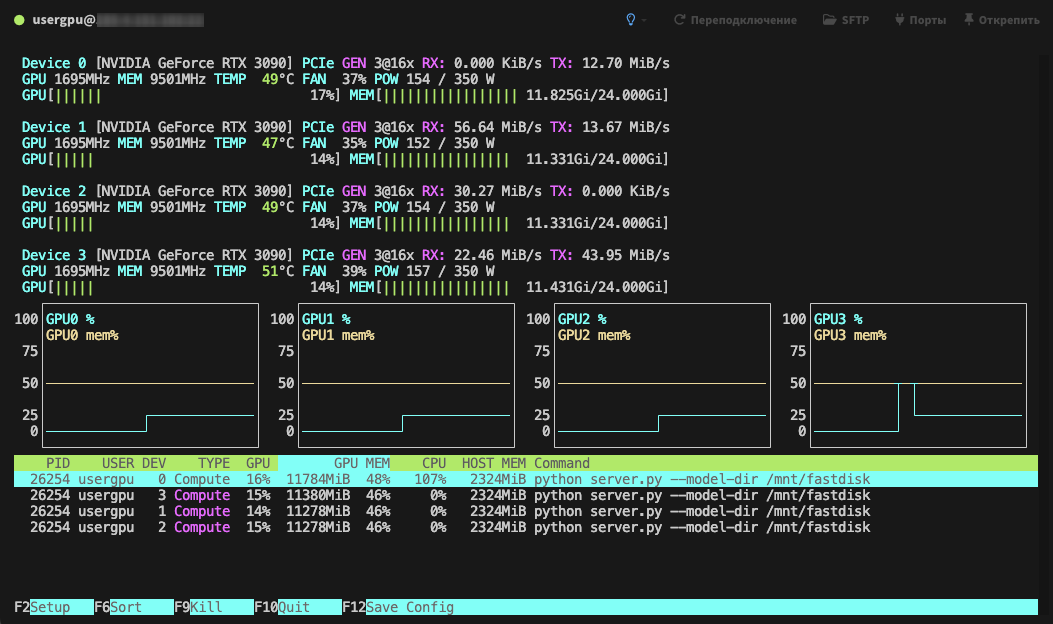
L'elaborazione verrà eseguita per impostazione predefinita su tutte le GPU disponibili, tenendo conto dei parametri precedentemente specificati:
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




