





Il vostro LLaMa 2 in Linux

Passo 1. Preparare il sistema operativo
Aggiornare la cache e i pacchetti
Aggiorniamo la cache dei pacchetti e aggiorniamo il sistema operativo prima di iniziare a configurare LLaMa 2. Si noti che per questa guida utilizziamo Ubuntu 22.04 LTS come sistema operativo:
sudo apt update && sudo apt -y upgradeInoltre, dobbiamo aggiungere Python Installer Packages (PIP), se non è già presente nel sistema:
sudo apt install python3-pipInstallare i driver NVIDIA®
È possibile utilizzare l'utilità automatica inclusa di default nelle distribuzioni Ubuntu:
sudo ubuntu-drivers autoinstallIn alternativa, è possibile installare manualmente i driver NVIDIA® utilizzando la nostra guida passo-passo. Non dimenticate di riavviare il server:
sudo shutdown -r nowPasso 2. Ottenere i modelli da MetaAI
Richiesta ufficiale
Aprite il seguente indirizzo nel vostro browser: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Compilare tutti i campi necessari, leggere il contratto d'uso e fare clic sul pulsante Agree and Continue. Dopo alcuni minuti (ore, giorni), riceverete uno speciale URL di download, che vi autorizza a scaricare i modelli per un periodo di 24 ore.
Clonare il repository
Prima di effettuare il download, verificare lo spazio di archiviazione disponibile:
df -hFilesystem Size Used Avail Use% Mounted on tmpfs 38G 3.3M 38G 1% /run /dev/sda2 99G 24G 70G 26% / tmpfs 189G 0 189G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/nvme0n1 1.8T 26G 1.7T 2% /mnt/fastdisk tmpfs 38G 8.0K 38G 1% /run/user/1000
Se i dischi locali sono smontati, seguire le istruzioni riportate in Partizionamento dei dischi in Linux. Questo è importante perché i modelli scaricati possono essere molto grandi e occorre pianificare in anticipo la loro posizione di archiviazione. In questo esempio, abbiamo un SSD locale montato nella directory /mnt/fastdisk. Apriamola:
cd /mnt/fastdiskCreare una copia del repository originale di LaMa:
git clone https://github.com/facebookresearch/llamaSe si verifica un errore di autorizzazione, è sufficiente concedere i permessi all'utenteergpu:
sudo chown -R usergpu:usergpu /mnt/fastdisk/Scaricamento tramite script
Aprire la directory scaricata:
cd llamaEseguire lo script:
./download.shPassare l'URL fornito da MetaAI e selezionare tutti i modelli necessari. Si consiglia di scaricare tutti i modelli disponibili per evitare di richiedere nuovamente l'autorizzazione. Tuttavia, se avete bisogno di un modello specifico, scaricate solo quello.
Test rapido tramite l'applicazione di esempio
Per iniziare, possiamo verificare la presenza di eventuali componenti mancanti. Se mancano librerie o applicazioni, il gestore dei pacchetti le installerà automaticamente:
pip install -e .Il passo successivo consiste nell'aggiungere nuovi file binari al PATH:
export PATH=/home/usergpu/.local/bin:$PATHEseguire l'esempio dimostrativo:
torchrun --nproc_per_node 1 /mnt/fastdisk/llama/example_chat_completion.py --ckpt_dir /mnt/fastdisk/llama-2-7b-chat/ --tokenizer_path /mnt/fastdisk/llama/tokenizer.model --max_seq_len 512 --max_batch_size 6L'applicazione creerà un processo di calcolo sulla prima GPU e simulerà una semplice finestra di dialogo con richieste tipiche, generando le risposte con LaMa 2.
Passo 3. Ottenere llama.cpp
LLaMa C++ è un progetto creato dal fisico e sviluppatore di software bulgaro Georgi Gerganov. Contiene molte utili utility che facilitano il lavoro con questo modello di rete neurale. Tutte le parti di llama.cpp sono software open source e sono distribuite sotto la licenza MIT.
Clonare il repository
Aprire la directory di lavoro sull'SSD:
cd /mnt/fastdiskClonare il repository del progetto:
git clone https://github.com/ggerganov/llama.cpp.gitCompilare le applicazioni
Aprire la cartella clonata:
cd llama.cppAvviare il processo di compilazione con il seguente comando:
makePasso 4. Ottenere text-generation-webui
Clonare il repository
Aprire la directory di lavoro sull'SSD:
cd /mnt/fastdiskClonare il repository del progetto:
git clone https://github.com/oobabooga/text-generation-webui.gitInstallare i requisiti
Aprire la cartella scaricata:
cd text-generation-webuiControllare e installare tutti i componenti mancanti:
pip install -r requirements.txtPasso 5. Conversione di PTH in GGUF
Formati comuni
PTH (Python TorcH) - Un formato consolidato. Essenzialmente, è un archivio ZIP standard con un dizionario di stato PyTorch serializzato. Tuttavia, questo formato ha alternative più veloci, come GGML e GGUF.
GGML (Georgi Gerganov’s Machine Learning) - È un formato di file creato da Georgi Gerganov, l'autore di llama.cpp. Si basa su un'omonima libreria, scritta in C++, che ha aumentato in modo significativo le prestazioni dei modelli linguistici di grandi dimensioni. Ora è stato sostituito dal moderno formato GGUF.
GGUF (Georgi Gerganov’s Unified Format) - Un formato di file ampiamente utilizzato per gli LLM, supportato da diverse applicazioni. Offre maggiore flessibilità, scalabilità e compatibilità per la maggior parte dei casi d'uso.
script llama.cpp convert.py
Modifica i parametri del modello prima della conversione:
nano /mnt/fastdisk/llama-2-7b-chat/params.jsonCorreggere "vocab_size": -1 in "vocab_size": 32000. Salvare il file e uscire. Aprire quindi la cartella llama.cpp:
cd /mnt/fastdisk/llama.cppEseguire lo script che convertirà il modello in formato GGUF:
python3 convert.py /mnt/fastdisk/llama-2-7b-chat/ --vocab-dir /mnt/fastdisk/llamaSe tutti i passaggi precedenti sono corretti, si riceverà un messaggio come questo:
Wrote /mnt/fastdisk/llama-2-7b-chat/ggml-model-f16.gguf
Passo 6. WebUI
Come avviare la WebUI
Aprire la directory:
cd /mnt/fastdisk/text-generation-webui/Eseguire lo script di avvio con alcuni parametri utili:
- --model-dir indica il percorso corretto dei modelli
- --share crea un collegamento pubblico temporaneo (se non si vuole inoltrare una porta tramite SSH)
- --gradio-auth aggiunge l'autorizzazione con una login e una password (sostituire user:password con la propria)
./start_linux.sh --model-dir /mnt/fastdisk/llama-2-7b-chat/ --share --gradio-auth user:passwordDopo l'avvio, si riceverà un link di condivisione locale e temporaneo per l'accesso:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://e9a61c21593a7b251f.gradio.live
Questo link di condivisione scade tra 72 ore.
Caricare il modello
Autorizzate la WebUI utilizzando il nome utente e la password selezionati e seguite questi 5 semplici passaggi:
- Passare alla scheda Model.
- Selezionare ggml-model-f16.gguf dal menu a discesa.
- Scegliere il numero di livelli che si desidera calcolare sulla GPU (n-gpu-layers).
- Scegliere il numero di thread da avviare (threads).
- Fare clic sul pulsante Load.
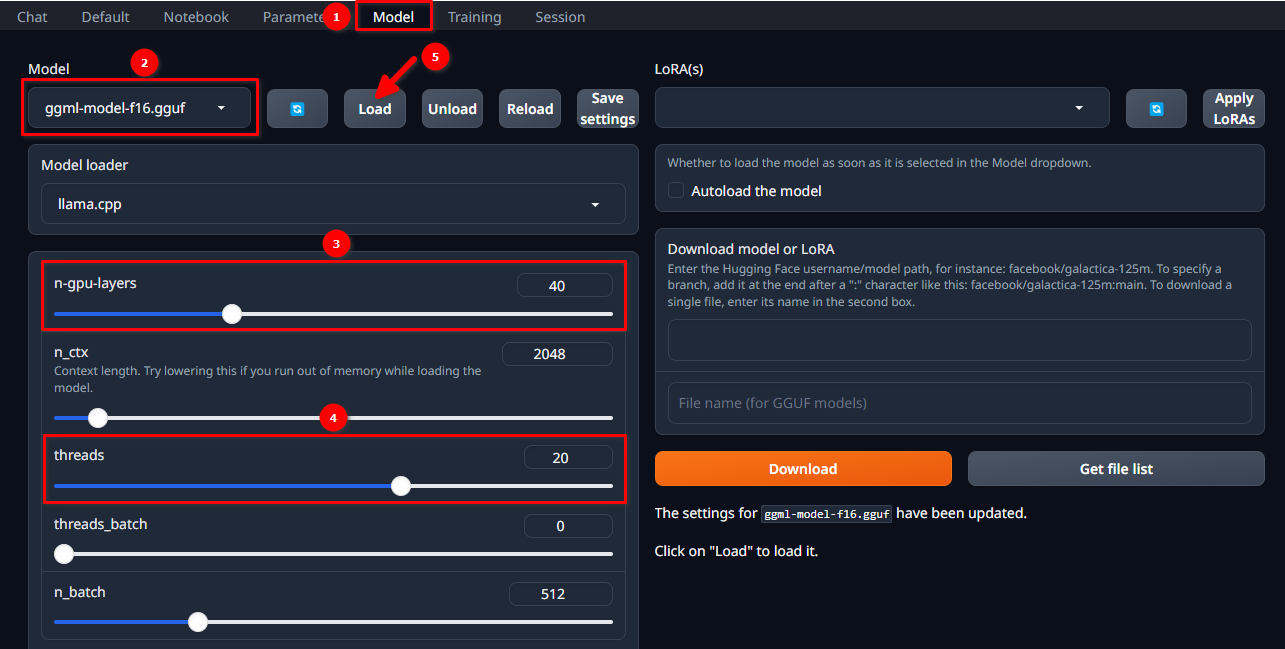
Avvio della finestra di dialogo
Cambiare la scheda in Chat, digitare la richiesta e fare clic su Generate:
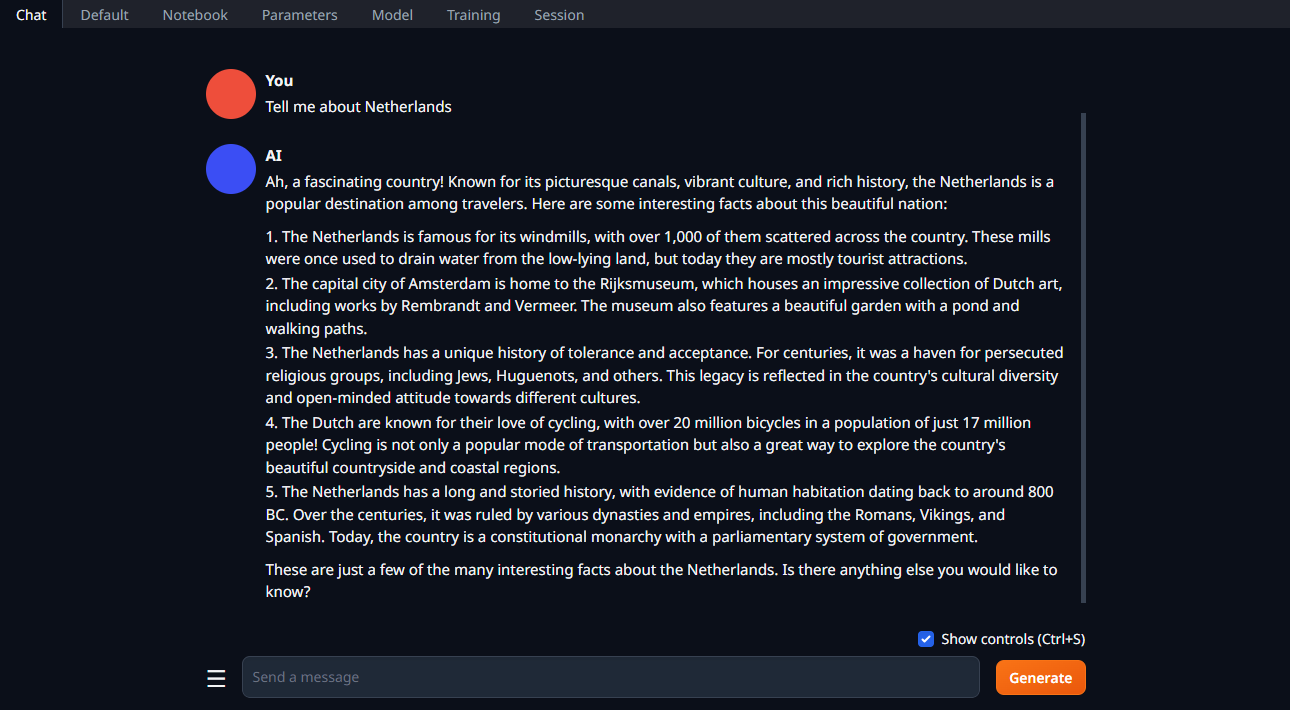
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




