





Llama 3 usando Hugging Face

Il 18 aprile 2024 è stato rilasciato Llama 3, il nuovo modello linguistico di MetaAI. Agli utenti sono state presentate due versioni: 8B e 70B. La prima versione contiene più di 15.000 token ed è stata addestrata su dati validi fino a marzo 2023. La seconda versione, più ampia, è stata addestrata su dati validi fino a dicembre 2023.
Fase 1. Preparare il sistema operativo
Aggiornare la cache e i pacchetti
Aggiorniamo la cache dei pacchetti e aggiorniamo il sistema operativo prima di iniziare a configurare LLaMa 3. Si noti che per questa guida utilizziamo Ubuntu 22.04 LTS come sistema operativo:
sudo apt update && sudo apt -y upgradeInoltre, dobbiamo aggiungere Python Installer Packages (PIP), se non è già presente nel sistema:
sudo apt install python3-pipInstallare i driver NVIDIA®
È possibile utilizzare l'utilità automatica inclusa di default nelle distribuzioni Ubuntu:
sudo ubuntu-drivers autoinstallIn alternativa, è possibile installare i driver NVIDIA® manualmente. Non dimenticate di riavviare il server:
sudo shutdown -r nowPasso 2. Ottenere il modello
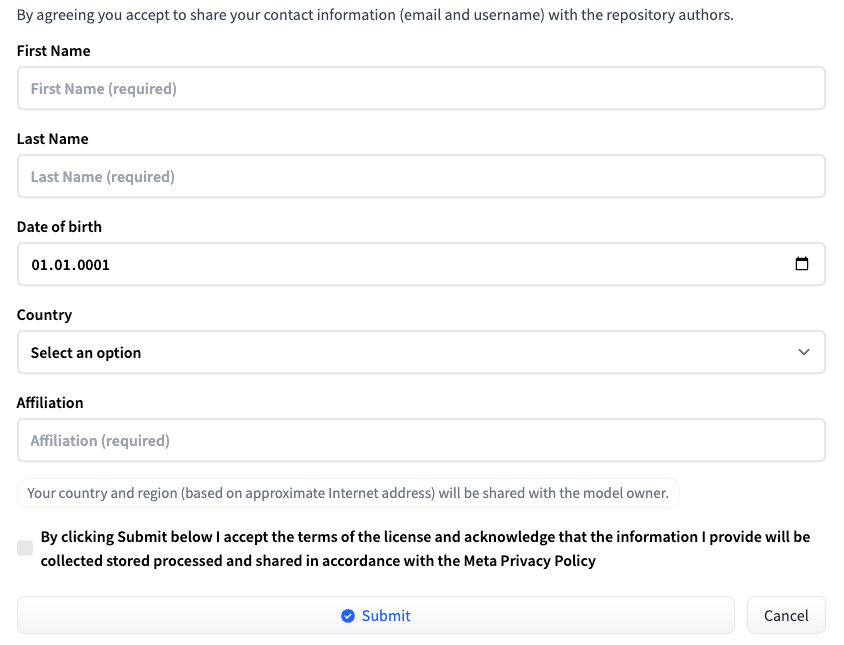
Accedere a Hugging Face utilizzando il proprio nome utente e la propria password. Andare alla pagina corrispondente alla versione di LLM desiderata: Meta-Llama-3-8B o Meta-Llama-3-70B. Al momento della pubblicazione di questo articolo, l'accesso al modello è fornito su base individuale. Compilare un breve modulo e fare clic sul pulsante Submit:
Richiesta di accesso a HF
Riceverete un messaggio che vi informa che la vostra richiesta è stata inoltrata:
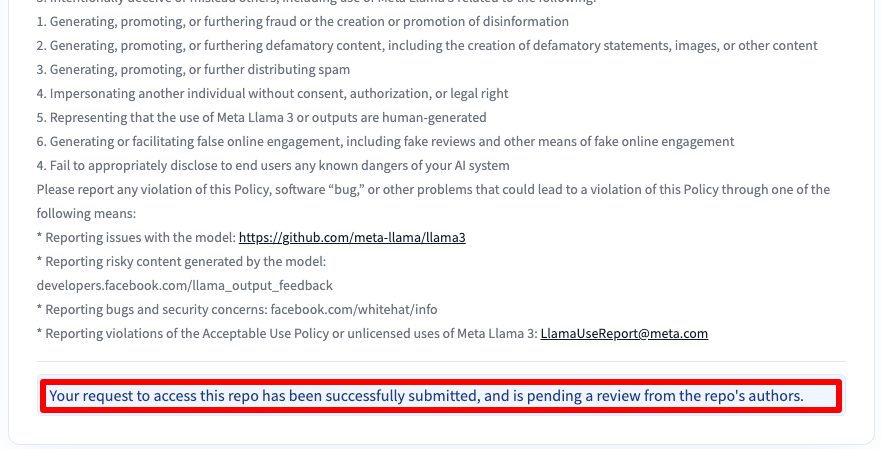
L'accesso avverrà dopo 30-40 minuti e sarete avvisati via e-mail.
Aggiungere la chiave SSH a HF
Generare e aggiungere una chiave SSH da utilizzare in Hugging Face:
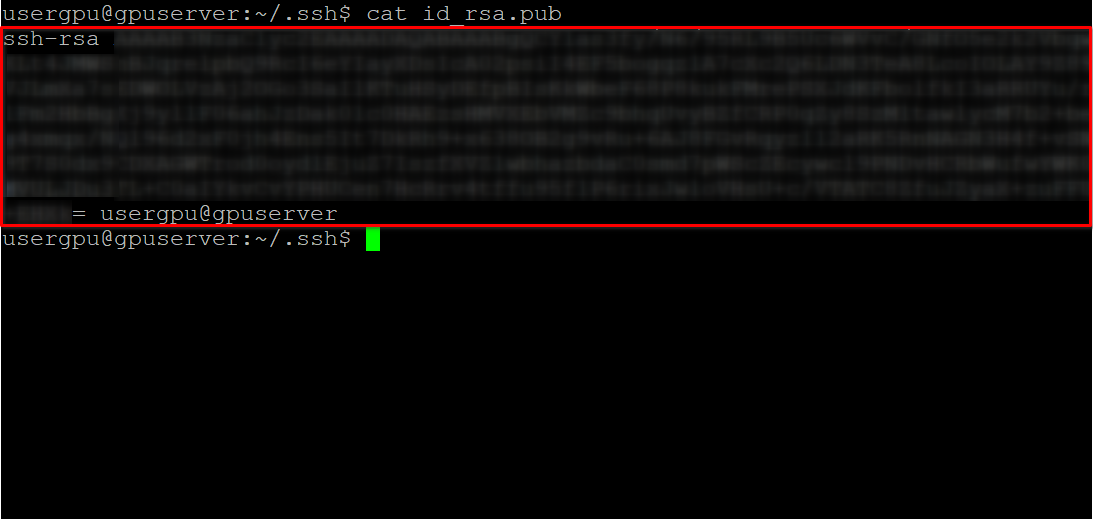
cd ~/.ssh && ssh-keygenQuando la coppia di chiavi è stata generata, è possibile visualizzare la chiave pubblica nell'emulatore di terminale:
cat id_rsa.pubCopiare tutte le informazioni a partire da ssh-rsa e fino a usergpu@gpuserver come mostrato nella seguente schermata:
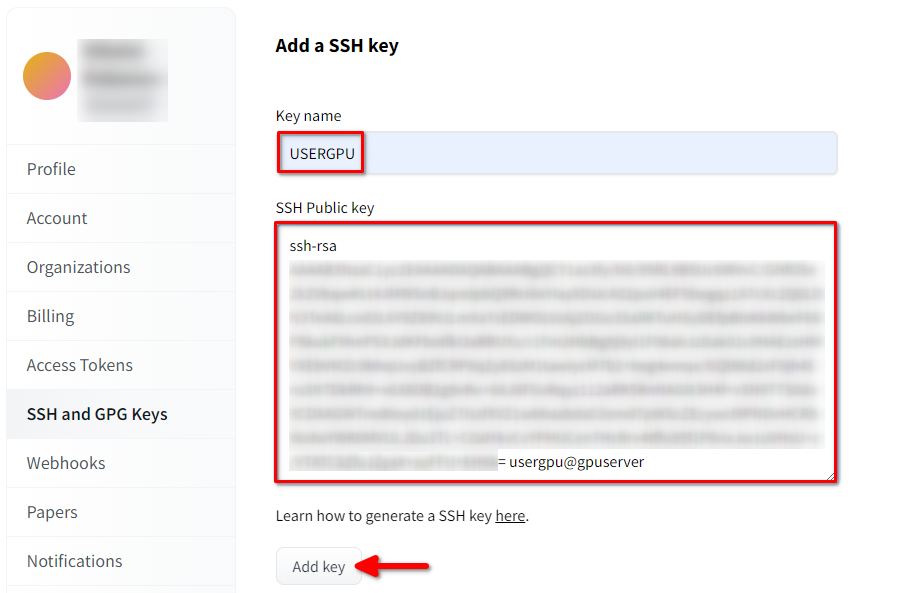
Aprire le impostazioni del profilo di Hugging Face. Scegliere quindi SSH and GPG Keys e fare clic sul pulsante Aggiungi chiave SSH:
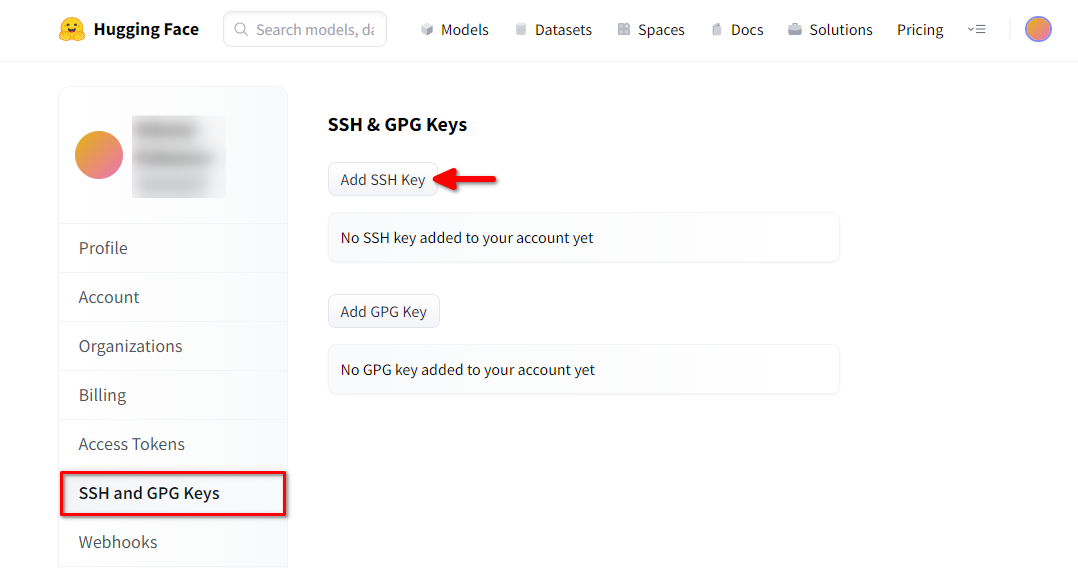
Compilare Key name e incollare SSH Public key copiato dal terminale. Salvare la chiave premendo Add key:
Ora il vostro account HF è collegato alla chiave SSH pubblica. La seconda parte (chiave privata) è memorizzata sul server. Il passo successivo consiste nell'installare un'estensione specifica di Git LFS (Large File Storage), utilizzata per scaricare file di grandi dimensioni come i modelli di reti neurali. Aprire la propria home directory:
cd ~/Scaricare ed eseguire lo script di shell. Questo script installa un nuovo repository di terze parti con git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashOra è possibile installarlo utilizzando il gestore di pacchetti standard:
sudo apt-get install git-lfsConfiguriamo git per usare il nostro nickname HF:
git config --global user.name "John"E collegato all'account di posta elettronica HF:
git config --global user.email "john.doe@example.com"Scarica il modello
Aprire la directory di destinazione:
cd /mnt/fastdiskE avviare il download del repository. Per questo esempio abbiamo scelto la versione 8B:
git clone git@hf.co:meta-llama/Meta-Llama-3-8BQuesto processo richiede fino a 5 minuti. È possibile monitorare questo processo eseguendo il seguente comando in un'altra console SSH:
watch -n 0.5 df -hQui si vedrà come lo spazio libero sul disco montato si riduce, assicurando che il download procede e che i dati vengono salvati. Lo stato si aggiorna ogni mezzo secondo. Per interrompere manualmente la visualizzazione, premere la scorciatoia Ctrl + C.
In alternativa, è possibile installare btop e monitorare il processo utilizzando questa utility:
sudo apt -y install btop && btop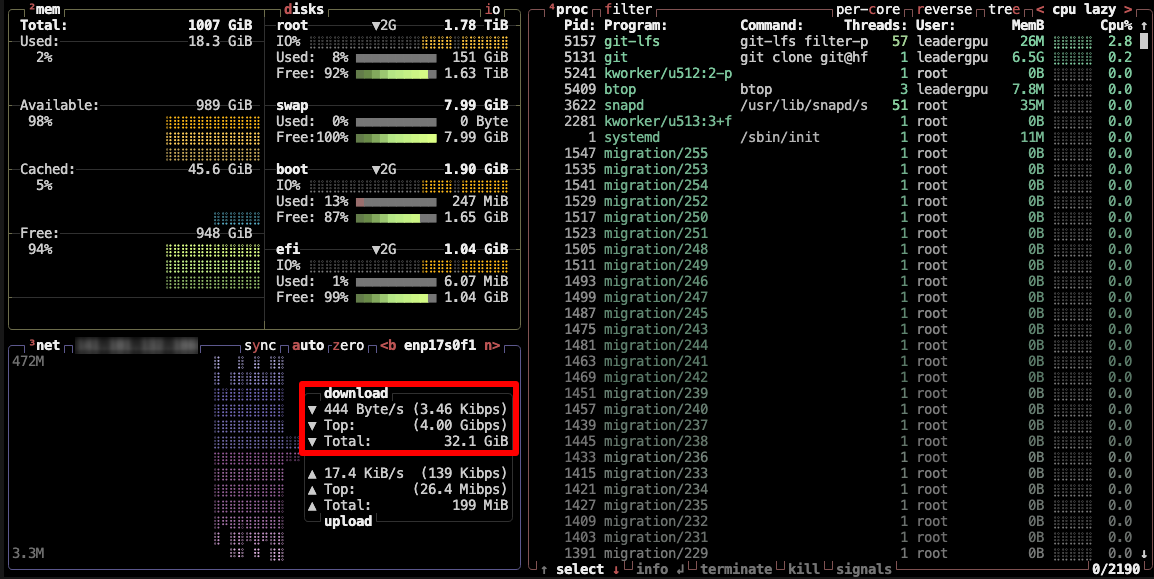
Per uscire dall'utilità btop, premere il tasto Esc e selezionare Quit.
Passo 3. Eseguire il modello
Aprire la directory:
cd /mnt/fastdiskScaricare il repository di Llama 3:
git clone https://github.com/meta-llama/llama3Cambiare la directory:
cd llama3Eseguire l'esempio:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir /mnt/fastdisk/Meta-Llama-3-8B/original \
--tokenizer_path /mnt/fastdisk/Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 \
--max_batch_size 4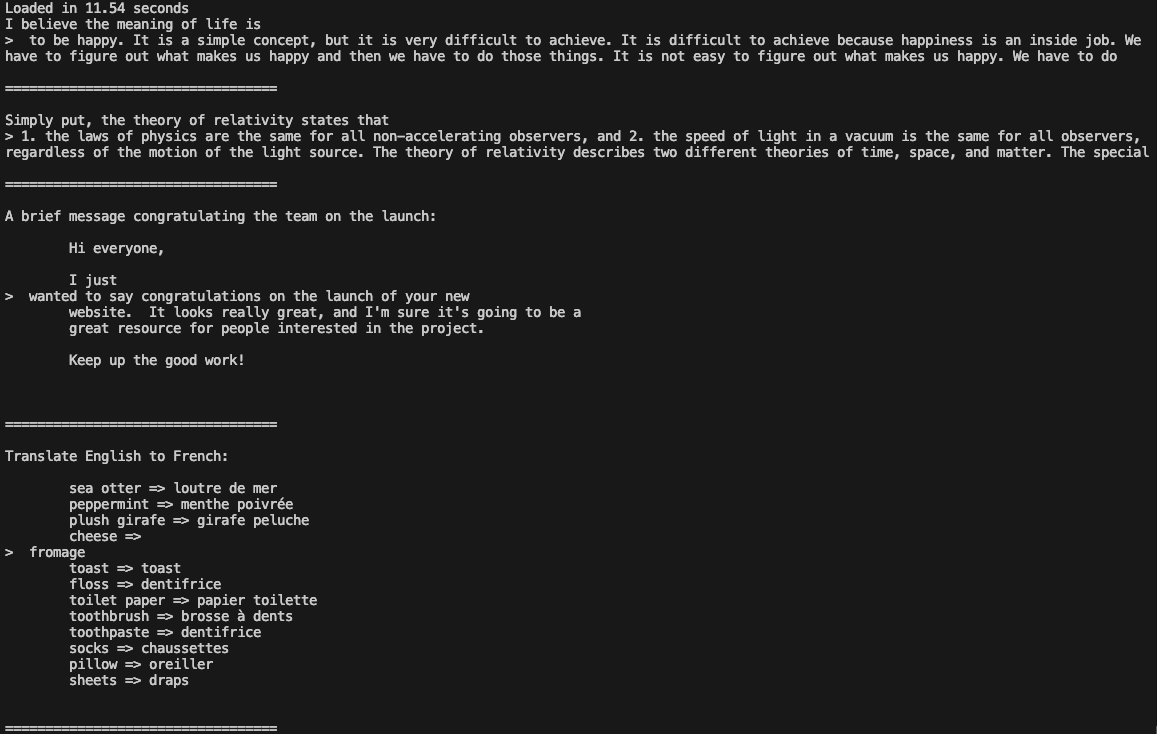
Ora è possibile utilizzare Llama 3 nelle proprie applicazioni.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




