





Qwen 2 vs Llama 3

I grandi modelli linguistici (LLM) hanno avuto un impatto significativo sulla nostra vita. Nonostante la comprensione della loro struttura interna, questi modelli rimangono un punto focale per gli scienziati che spesso li paragonano a una "scatola nera". Il risultato finale dipende non solo dalla progettazione del LLM, ma anche dalla sua formazione e dai dati utilizzati per l'addestramento.
Mentre gli scienziati trovano opportunità di ricerca, gli utenti finali sono interessati principalmente a due cose: velocità e qualità. Questi criteri giocano un ruolo fondamentale nel processo di selezione. Per confrontare accuratamente due LLM, è necessario standardizzare molti fattori apparentemente non correlati.
L'apparecchiatura utilizzata per le interferenze e l'ambiente software, compresi il sistema operativo, le versioni dei driver e i pacchetti software, hanno l'impatto più significativo. È essenziale selezionare una versione di LLM che funzioni su diverse apparecchiature e scegliere una metrica di velocità facilmente comprensibile.
Abbiamo scelto come parametro "tokens per secondo" (tokens/s). È importante notare che un token ≠ una parola. L'LLM scompone le parole in componenti più semplici, tipiche di una lingua specifica, denominate token.
La prevedibilità statistica del carattere successivo varia da una lingua all'altra, quindi la tokenizzazione sarà diversa. Ad esempio, in inglese, ogni 75 parole si ricavano circa 100 token. Nelle lingue che utilizzano l'alfabeto cirillico, il numero di token per parola può essere maggiore. Quindi, 75 parole in una lingua cirillica, come il russo, potrebbero equivalere a 120-150 token.
È possibile verificarlo utilizzando lo strumento Tokenizer di OpenAI. Questo strumento mostra in quanti tokens viene suddiviso un frammento di testo, rendendo i "tokens per secondo" un buon indicatore della velocità e delle prestazioni di elaborazione del linguaggio naturale di un LLM.
Ogni test è stato condotto sul sistema operativo Ubuntu 22.04 LTS con i driver NVIDIA® versione 535.183.01 e il toolkit NVIDIA® CUDA® 12.5 installato. Le domande sono state formulate per valutare la qualità e la velocità dell'LLM. La velocità di elaborazione di ogni risposta è stata registrata e contribuirà al valore medio per ogni configurazione testata.
Abbiamo iniziato a testare diverse GPU, dai modelli più recenti a quelli più vecchi. Una condizione fondamentale per il test è stata quella di misurare le prestazioni di una sola GPU, anche se nella configurazione del server erano presenti più GPU. Questo perché le prestazioni di una configurazione con più GPU dipendono da fattori aggiuntivi come la presenza di un'interconnessione ad alta velocità tra di esse (NVLink).
Oltre alla velocità, abbiamo cercato di valutare anche la qualità delle risposte su una scala a 5 punti, dove 5 rappresenta il risultato migliore. Queste informazioni sono fornite solo per una comprensione generale. Ogni Volta™ porremo le stesse domande alla rete neurale e cercheremo di capire quanto accuratamente ognuna di esse comprenda ciò che l'utente vuole da essa.
Qwen 2
Recentemente, un team di sviluppatori di Alibaba Group ha presentato la seconda versione della rete neurale generativa Qwen. Comprende 27 lingue ed è ben ottimizzata per esse. Qwen 2 è disponibile in diverse dimensioni per facilitarne l'implementazione su qualsiasi dispositivo (da sistemi embedded ad alta limitazione di risorse a server dedicati con GPU):
- 0.5B: adatto per IoT e sistemi embedded;
- 1.5B: una versione estesa per i sistemi embedded, utilizzata quando le capacità di 0.5B non sono sufficienti;
- 7B: modello di medie dimensioni, adatto all'elaborazione del linguaggio naturale;
- 57B: modello di grandi dimensioni ad alte prestazioni, adatto ad applicazioni complesse;
- 72B: il modello Qwen 2 definitivo, progettato per risolvere i problemi più complessi ed elaborare grandi volumi di dati.
Le versioni 0.5B e 1.5B sono state addestrate su set di dati con una lunghezza di contesto di 32K. Le versioni 7B e 72B erano già state addestrate su un contesto di 128K. Il modello di compromesso 57B è stato addestrato su set di dati con un contesto di 64K. I creatori hanno definito Qwen 2 come un analogo di Llama 3 in grado di risolvere gli stessi problemi, ma molto più velocemente.
Llama 3
La terza versione della rete neurale generativa della famiglia MetaAI Llama è stata introdotta nell'aprile 2024. A differenza di Qwen 2, è stata rilasciata in due sole versioni: 8B e 70B. Questi modelli sono stati posizionati come uno strumento universale per risolvere molti problemi in vari casi. Continuava la tendenza al multilinguismo e alla multimodalità, diventando al contempo più veloce delle versioni precedenti e supportando una maggiore lunghezza del contesto.
I creatori di Llama 3 hanno cercato di perfezionare i modelli per ridurre la percentuale di allucinazioni statistiche e aumentare la varietà delle risposte. Llama 3 è quindi in grado di dare consigli pratici, aiutare a scrivere una lettera commerciale o speculare su un argomento specificato dall'utente. I dataset su cui sono stati addestrati i modelli di Llama 3 avevano una lunghezza del contesto di 128K e più del 5% includeva dati in 30 lingue. Tuttavia, come si legge nel comunicato stampa, le prestazioni di generazione in inglese saranno significativamente superiori a quelle in qualsiasi altra lingua.
Confronto
NVIDIA® RTX™ A6000
Iniziamo le nostre misurazioni di velocità con la GPU NVIDIA® RTX™ A6000, basata sull'architettura Ampere (da non confondere con la NVIDIA® RTX™ A6000 Ada). Questa scheda ha caratteristiche molto modeste, ma allo stesso tempo dispone di 48 GB di VRAM, che le permettono di operare con modelli di reti neurali piuttosto grandi. Purtroppo, la bassa velocità di clock e la larghezza di banda sono le ragioni della bassa velocità di inferenza degli LLM testuali.
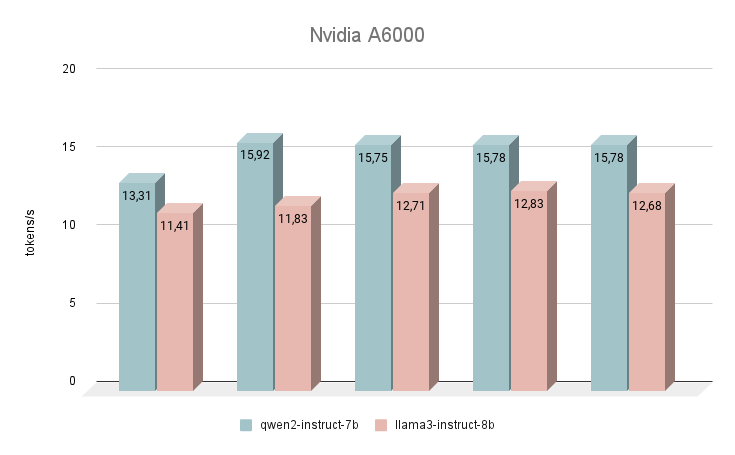
Subito dopo il lancio, la rete neurale Qwen 2 ha iniziato a superare le prestazioni di Llama 3. Rispondendo alle stesse domande, la differenza media di velocità è stata del 24% a favore di Qwen 2. La velocità di generazione delle risposte è stata dell'ordine di 11-16 token al secondo. Si tratta di una velocità 2-3 volte superiore rispetto al tentativo di generazione anche su una CPU potente, ma nella nostra valutazione questo è il risultato più modesto.
NVIDIA® RTX™ 3090
Anche la prossima GPU è costruita sull'architettura Ampere, ha una memoria video 2 volte inferiore, ma allo stesso tempo opera a una frequenza superiore (19500 MHz contro 16000 Mhz). Anche la larghezza di banda della memoria video è maggiore (936,2 GB/s contro 768 GB/s). Entrambi questi fattori aumentano notevolmente le prestazioni della RTX™ 3090, anche tenendo conto del fatto che ha 256 core CUDA® in meno.
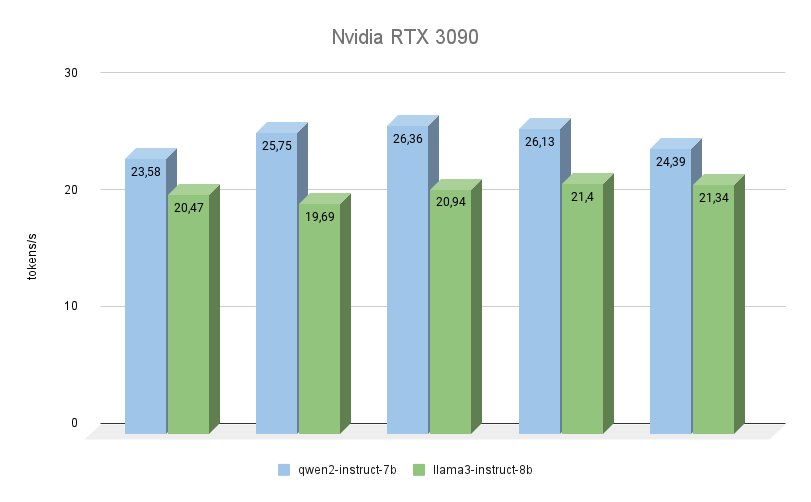
Qui si vede chiaramente che Qwen 2 è molto più veloce (fino al 23%) di Llama 3 nell'esecuzione degli stessi compiti. Per quanto riguarda la qualità della generazione, il supporto multilingue di Qwen 3 è davvero degno di lode e il modello risponde sempre nella stessa lingua in cui è stata posta la domanda. Con Llama 3, a questo proposito, capita spesso che il modello capisca la domanda stessa, ma preferisca formulare le risposte in inglese.
NVIDIA® RTX™ 4090
Ora la cosa più interessante: vediamo come se la cava la NVIDIA® RTX™ 4090, costruita sull'architettura Ada Lovelace, dal nome della matematica inglese Augusta Ada King, contessa di Lovelace. Ada Lovelace è diventata famosa per essere stata la prima programmatrice nella storia dell'umanità, e all'epoca in cui scrisse il suo primo programma non esisteva un computer assemblato in grado di eseguirlo. Tuttavia, è stato riconosciuto che l'algoritmo descritto da Ada per il calcolo dei numeri di Bernoulli è stato il primo programma al mondo scritto per essere eseguito su un computer.
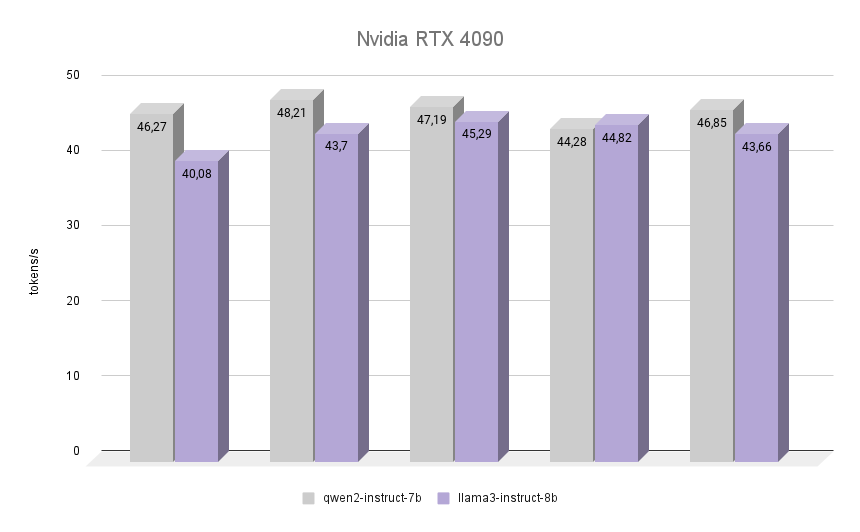
Il grafico mostra chiaramente che la RTX™ 4090 ha affrontato l'inferenza di entrambi i modelli con una velocità quasi doppia. È interessante notare che in una delle iterazioni Llama 3 è riuscito a superare Qwen 2 dell'1,2%. Tuttavia, tenendo conto delle altre iterazioni, Qwen 2 ha mantenuto la sua leadership, rimanendo più veloce di Llama 3 del 7%. In tutte le iterazioni, la qualità delle risposte di entrambe le reti neurali è stata elevata, con un numero minimo di allucinazioni. L'unico difetto è che in rari casi uno o due caratteri cinesi sono stati mescolati nelle risposte, il che non ha influito in alcun modo sul significato complessivo.
NVIDIA® RTX™ A40
La successiva scheda NVIDIA® RTX™ A40, su cui abbiamo eseguito test simili, è nuovamente costruita sull'architettura Ampere e dispone di 48 GB di memoria video sulla scheda madre. Rispetto alla RTX™ 3090, questa memoria è leggermente più veloce (20000 MHz contro 19500 MHz), ma ha una larghezza di banda inferiore (695,8 GB/s contro 936,2 GB/s). La situazione è compensata dal maggior numero di core CUDA® (10752 contro 10496), che nel complesso permette alla RTX™ A40 di essere leggermente più veloce della RTX™ 3090.
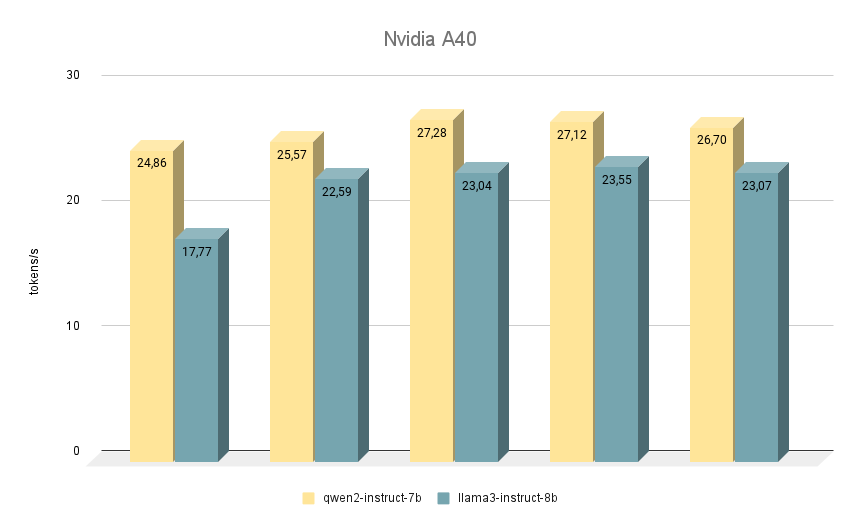
Per quanto riguarda il confronto della velocità dei modelli, anche in questo caso Qwen 2 è superiore a Llama 3 in tutte le iterazioni. Quando viene eseguito su RTX™ A40, la differenza di velocità è di circa il 15% a parità di risposte. In alcuni compiti, Qwen 2 ha fornito informazioni un po' più importanti, mentre Llama 3 è stato il più specifico possibile e ha fornito esempi. Ciononostante, è necessario ricontrollare tutto, poiché a volte entrambi i modelli iniziano a produrre risposte controverse.
NVIDIA® L20
L'ultimo partecipante al nostro test è stato l'NVIDIA® L20. Questa GPU è costruita, come la RTX™ 4090, sull'architettura Ada Lovelace. Si tratta di un modello abbastanza nuovo, presentato nell'autunno del 2023. A bordo ha 48 GB di memoria video e 11776 CUDA® core. La larghezza di banda della memoria è inferiore a quella della RTX™ 4090 (864 GB/s contro 936,2 GB/s), così come la frequenza effettiva. Pertanto, i punteggi di inferenza NVIDIA® L20 di entrambi i modelli saranno più vicini al 3090 che al 4090.
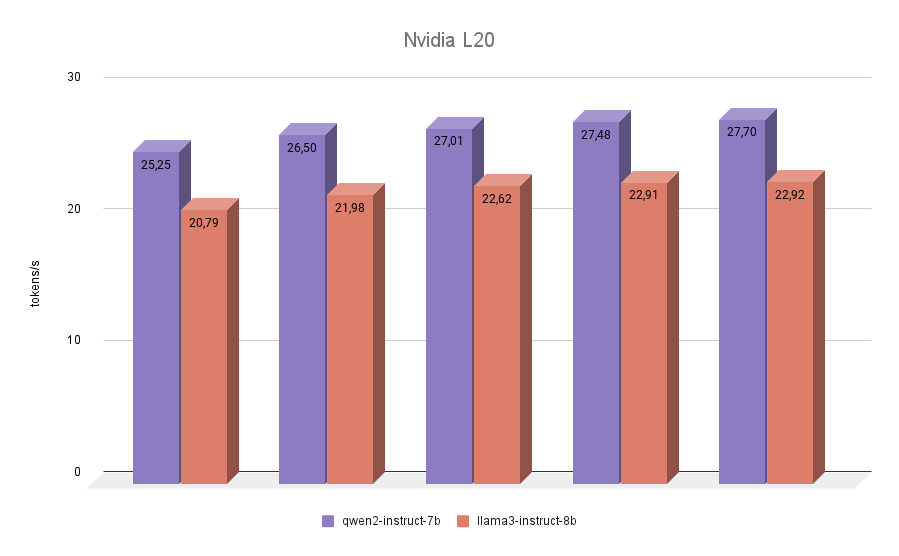
Il test finale non ha riservato sorprese. Qwen 2 è risultato più veloce di Llama 3 in tutte le iterazioni.
Conclusione
Riuniamo tutti i risultati raccolti in un unico grafico. Qwen 2 è risultato più veloce di Llama 3 dal 7% al 24% a seconda della GPU utilizzata. In base a ciò, possiamo concludere chiaramente che se si desidera ottenere inferenze ad alta velocità da modelli come Qwen 2 o Llama 3 su configurazioni a singola GPU, il leader indiscusso sarà la RTX™ 3090. Una possibile alternativa potrebbe essere l'A40 o l'L20. Ma non vale la pena di eseguire l'inferenza di questi modelli su schede Ampere di generazione A6000.

Non abbiamo volutamente menzionato nei test le schede con una quantità inferiore di memoria video, ad esempio la NVIDIA® RTX™ 2080Ti, poiché non è possibile inserirvi i modelli 7B o 8B di cui sopra senza quantizzazione. Il modello Qwen 2 da 1,5B, purtroppo, non ha risposte di alta qualità e non può sostituire completamente il modello 7B.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




