





Come funziona Ollama

Ollama è uno strumento per l'esecuzione di modelli di reti neurali di grandi dimensioni a livello locale. L'uso di servizi pubblici è spesso percepito dalle aziende come un potenziale rischio di fuga di dati riservati e sensibili. Per questo motivo, l'implementazione di LLM su un server controllato consente di gestire in modo indipendente i dati presenti su di esso, sfruttando al contempo i punti di forza di LLM.
In questo modo si evita anche la spiacevole situazione di vendor lock-in, in cui qualsiasi servizio pubblico può interrompere unilateralmente la fornitura di servizi. Naturalmente, l'obiettivo iniziale è quello di consentire l'uso delle reti neurali generative in luoghi dove l'accesso a Internet è assente o difficile (ad esempio, in aereo).
L'idea è quella di semplificare l'avvio, il controllo e la messa a punto degli LLM. Invece di complesse istruzioni in più fasi, Ollama consente di eseguire un semplice comando e di ricevere il risultato finale dopo qualche tempo. Il risultato sarà presentato simultaneamente sotto forma di modello di rete neurale locale, con il quale è possibile comunicare utilizzando un'interfaccia web e un'API per una facile integrazione in altre applicazioni.
Per molti sviluppatori, questo è diventato uno strumento molto utile, poiché nella maggior parte dei casi è stato possibile integrare Ollama con l'IDE utilizzato e ricevere raccomandazioni o codice già pronto scritto direttamente mentre si lavora all'applicazione.
Inizialmente Ollama era destinato solo ai computer con sistema operativo macOS, ma in seguito è stato portato su Linux e Windows. È stata rilasciata anche una versione speciale per lavorare in ambienti containerizzati come Docker. Attualmente, funziona ugualmente bene sia sui desktop che su qualsiasi server dedicato con una GPU. Ollama supporta la possibilità di passare da un modello all'altro e massimizza tutte le risorse disponibili. Naturalmente, questi modelli potrebbero non avere le stesse prestazioni su un normale desktop, ma funzionano in modo adeguato.
Come installare Ollama
Ollama può essere installato in due modi: senza usare la containerizzazione, usando uno script di installazione, e come contenitore Docker già pronto. Il primo metodo facilita la gestione dei componenti del sistema e dei modelli installati, ma è meno tollerante ai guasti. Il secondo metodo è più tollerante ai guasti, ma quando lo si utilizza è necessario tenere conto di tutti gli aspetti inerenti ai container: una gestione leggermente più complessa e un approccio diverso all'archiviazione dei dati.
Indipendentemente dal metodo scelto, sono necessari diversi passaggi aggiuntivi per preparare il sistema operativo.
I prerequisiti
Aggiornare il repository della cache dei pacchetti e i pacchetti installati:
sudo apt update && sudo apt -y upgradeInstallare tutti i driver GPU necessari usando la funzione di installazione automatica:
sudo ubuntu-drivers autoinstallRiavviare il server:
sudo shutdown -r nowInstallazione tramite script
Il seguente script rileva l'architettura del sistema operativo corrente e installa la versione appropriata di Ollama:
curl -fsSL https://ollama.com/install.sh | shDurante il funzionamento, lo script creerà un utente separato ollama, sotto il quale verrà lanciato il demone corrispondente. Per inciso, lo stesso script funziona bene in WSL2, consentendo l'installazione della versione Linux di Ollama su Windows Server.
Installazione tramite Docker
Esistono vari metodi per installare Docker Engine su un server. Il modo più semplice è quello di utilizzare uno script specifico che installa la versione corrente di Docker. Questo approccio è efficace per Ubuntu Linux, dalla versione 20.04 (LTS) fino all'ultima versione, Ubuntu 24.04 (LTS):
curl -sSL https://get.docker.com/ | shAffinché i contenitori Docker interagiscano correttamente con la GPU, è necessario installare un toolkit aggiuntivo. Poiché non è disponibile nei repository di base di Ubuntu, è necessario aggiungere un repository di terze parti utilizzando il seguente comando:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listAggiornare il repository della cache dei pacchetti:
sudo apt updateE installare il pacchetto nvidia-container-toolkit:
sudo apt install nvidia-container-toolkitNon dimenticare di riavviare il demone docker tramite systemctl:
sudo systemctl restart dockerÈ il momento di scaricare ed eseguire Ollama con l'interfaccia web Open-WebUI:
sudo docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaAprire il browser web e navigare su http://[server-ip]:3000:
Scaricare ed eseguire i modelli
Tramite riga di comando
È sufficiente eseguire il seguente comando:
ollama run llama3Tramite WebUI
Aprire Settings > Models, digitare il nome del modello necessario, ad esempio llama3 e fare clic sul pulsante con il simbolo di download:

Il modello verrà scaricato e installato automaticamente. Al termine, chiudere la finestra delle impostazioni e selezionare il modello scaricato. A questo punto è possibile iniziare a dialogare con esso:

Integrazione VSCode
Se avete installato Ollama utilizzando lo script di installazione, potete lanciare qualsiasi modello supportato quasi istantaneamente. Nel prossimo esempio, verrà eseguito il modello predefinito previsto dall'estensione Ollama Autocoder (openhermes2.5-mistral:7b-q4_K_M):
ollama run openhermes2.5-mistral:7b-q4_K_MPer impostazione predefinita, Ollama permette di lavorare attraverso un'API, consentendo solo connessioni dall'host locale. Pertanto, prima di installare e utilizzare l'estensione per Visual Studio Code, è necessario effettuare il port forwarding. In particolare, è necessario inoltrare la porta remota 11434 al computer locale. Un esempio di come farlo è riportato nel nostro articolo sulla WebUI di Easy Diffusion.
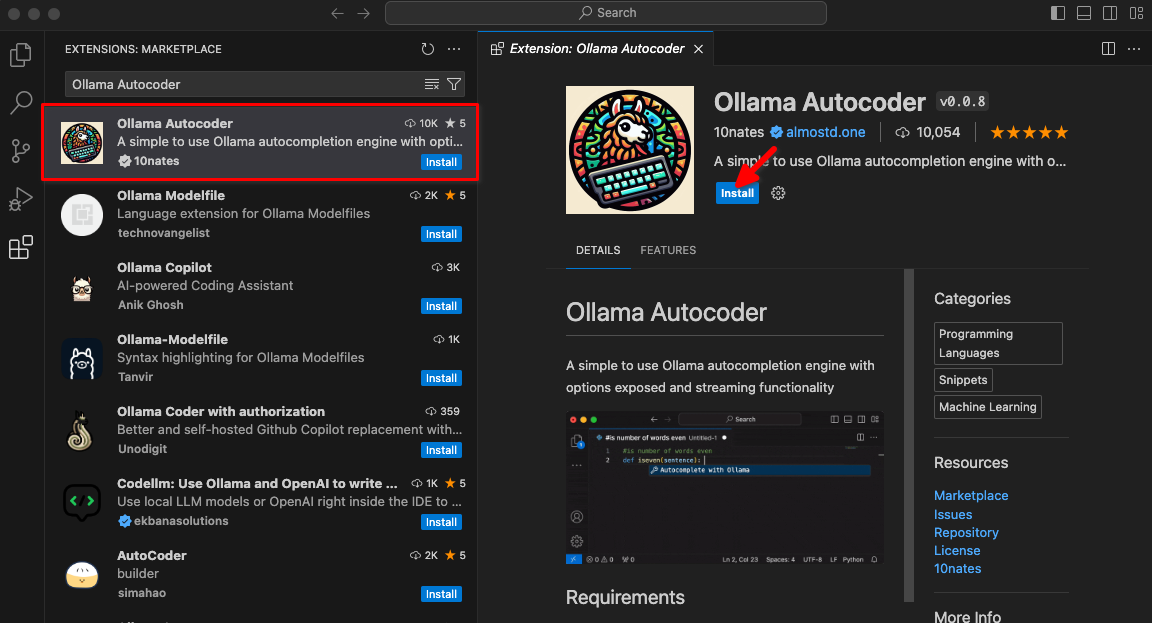
Digitare Ollama Autocoder in un campo di ricerca, quindi fare clic su Install:
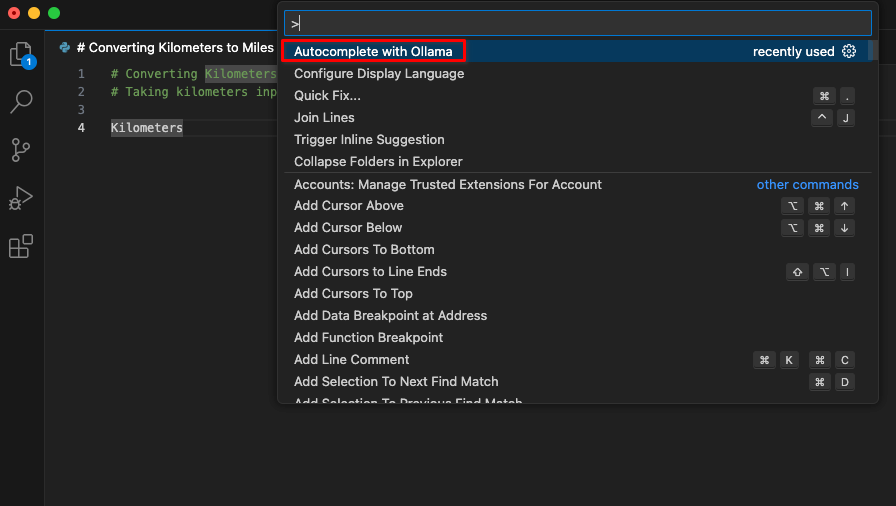
Dopo aver installato l'estensione, nella tavolozza dei comandi sarà disponibile una nuova voce intitolata Autocomplete with Ollama. Iniziare la codifica e avviare questo comando.
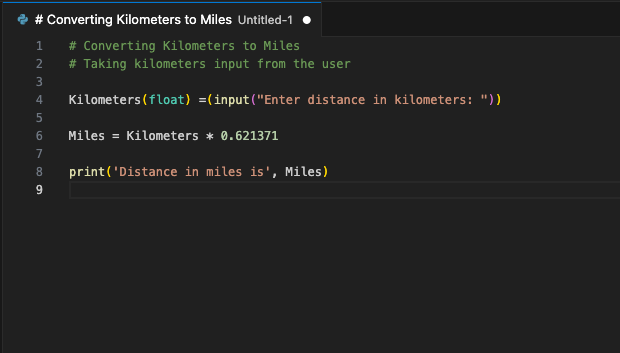
L'estensione si connetterà al server LeaderGPU utilizzando il port forwarding e, in pochi secondi, il codice generato verrà visualizzato sullo schermo:
È possibile assegnare questo comando a un tasto di scelta rapida. Utilizzatelo ogni Volta™ che volete integrare il vostro codice con un frammento generato. Questo è solo un esempio delle estensioni di VSCode disponibili. Il principio del port forwarding da un server remoto a un computer locale consente di configurare un singolo server con un LLM funzionante per un intero team di sviluppatori. Questa garanzia impedisce ad aziende terze o ad hacker di utilizzare il codice inviato.
Vedi anche:
Aggiornato: 04.01.2026
Pubblicato: 20.01.2025




